さて、今日はCaffeに関する記事を書いてみたいと思います。
Caffeは有名なDeep Learningのフレームワークです。同じDeep LearningのフレームワークとしてはTensorflowやChainerあたりも有名です。
今までこのブログではTensorflowに関する記事をいくつか書いてきましたが、この度Caffeも始めてみようと思い立ちました。
理由はいくつかありますが、
(1) まあ、いろいろ使えるに越したことはないよねー的な軽いノリ
(2) TensorflowはCのAPIあるけど、情報が不足しておりC++のプログラムとかに組み込んで使うのは使いにくい(仕事の関係上、C++にDeepLearningのコードを組み込んで使ったりする場面が多々ある)という理由(Caffeが使いやすいかは別としても、今はOpenCVのdnnモジュールとかからモデル読めたりするんで、割と使いやすいのではないかという期待)
(3) そもそも巷で見かける論文はCaffeで実装されていることが多い
特に三つ目の理由は結構大きいのではないかと思います。
とにかく、Caffeやってみようと思い立ったのはいいのですが、意外とこれがとっつきにくくて「じゃあ何からやったらいいの?」というところで結構困ってしまいました。
環境構築も一口に言いますが、どこまでやれば環境構築なの? みたいな話もありますよね。
今回は、まっさらな状態からCaffeでのDeep Learningをスタートさせ、MNISTという手書き数字画像の認識、訓練を行うところまで、まずやってみたいと思います。
目次
今回の環境
・OS : Windows10(64bit)
・GPU: GeForce GTX 950
・CUDA 8.0(導入済) 導入方法は過去記事を参照
手順
(1) Windows Caffeをダウンロード
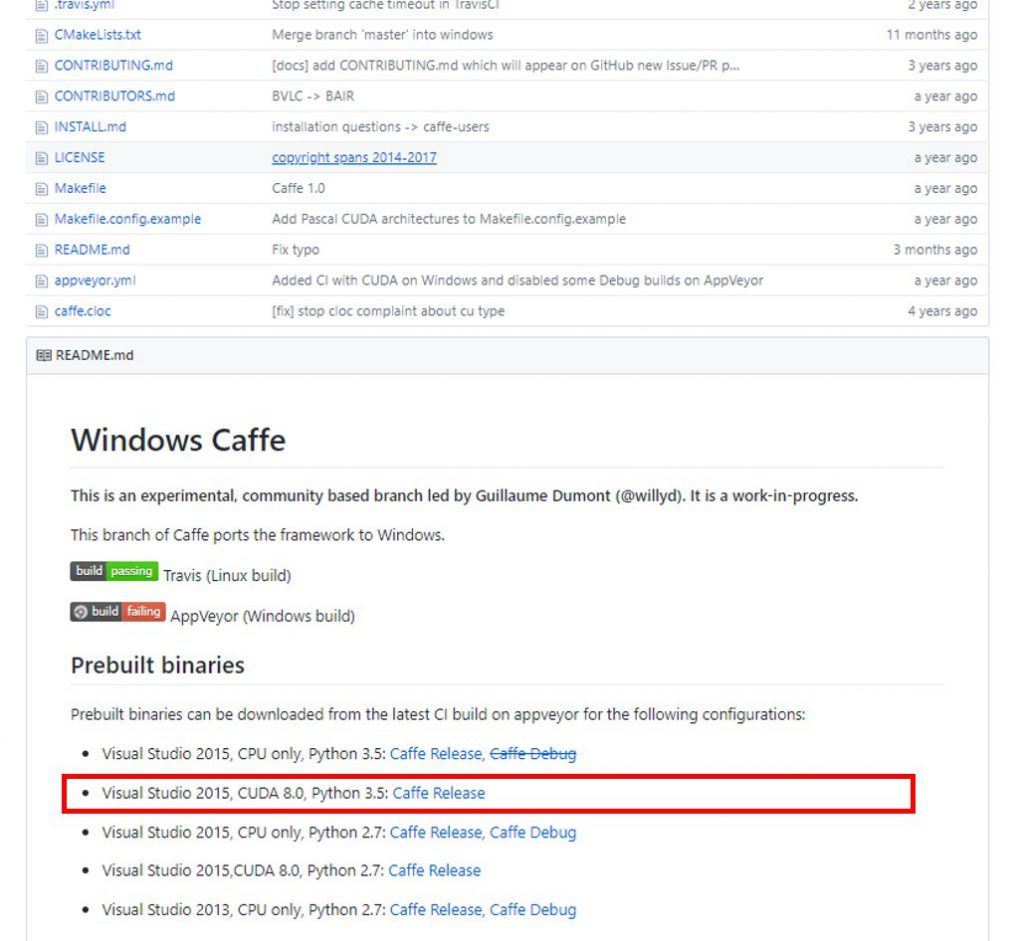
Windows Caffeをダウンロードします。ありがたいことに今はPrebuilt binariesというものがあるので、これを使ってしまいましょう。
以下のGithubのページの下部からダウンロード可能です。
外部サイト:BVLC/caffe at windows
一応、今使っているコンピュータには使えるGPUが入っており、CUDA8.0もインストールしているはずなので、わたしは「Visual Studio 2015, CUDA 8.0, Python 3.5」を選択しました。
もしCUDAを使えるGPUを搭載している人は、CUDAの環境構築が必要となると思いますので、次の記事をご参照ください。
過去記事①:CUDA8.0の導入と環境構築(Windows 10)
ダウンロードした「caffe.zip」を適当なフォルダに解凍します。
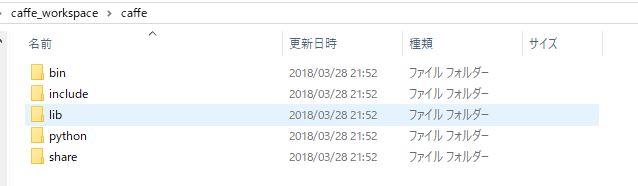
こんな感じで5つのフォルダができています。
「bin」フォルダの中にいろんな実行ファイルが入っていますが、これにいろいろな引数を渡すことで学習画像のデータセットを作ったり、訓練をしたり、テストをしたり、いろいろできてしまいます……というイメージです。
コーディングして、手を動かして、というアプローチもあるはずですが、最初ということで、これらを使って実際に訓練し、モデルを作ってみましょう。
(2) MNISTのデータのダウンロード
MNIST は手書き数字のデータセットです。
以下のような数字が記されたデータセットで、Deep Learningでは有名なデータセットであり、入門的な意味合いでよく使われています。


Deep Learningをする場合、データセット(大量の学習画像の固まり)を用意するのが何よりも大変です。
そこで、研究等を目的とし、画像そのものや、その画像の正解のラベルなどがセットされたデータセットが様々用意されています。
MNISTはその中で「0」~「9」の手書き数字に関するデータセットです。これは、例えば「5」と書かれた画像を入力すると、「5」と認識してくれるようなモデルを作成する問題と言えます。
実はCaffeのサンプルの中にはMNISTのデータを自動でダウンロードしてくれるシェルスクリプトみたいなのが用意されていたりもするのですが、今回は自分の手でMNISTのデータをダウンロードしてきてみましょう。
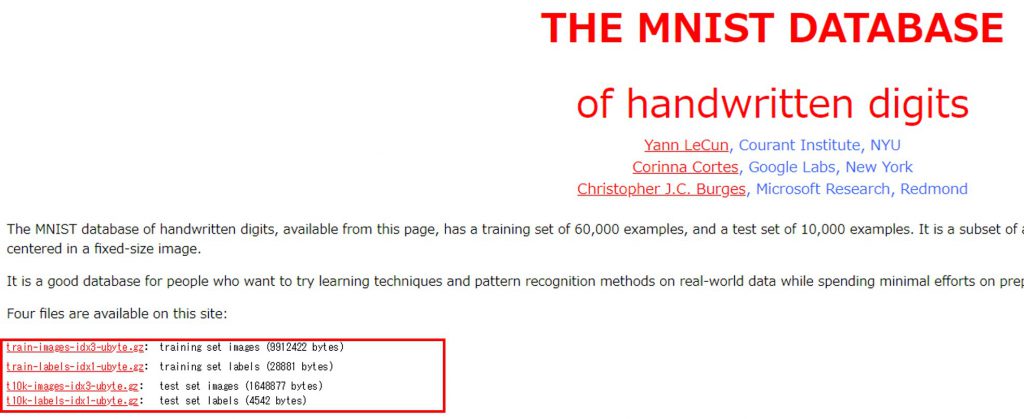
外部サイト:THE MNIST DATABASE
上記サイトより、以下の四つのファイルをダウンロードします。
・train-labels-idx1-ubyte.gz
・train-images-idx3-ubyte.gz
・t10k-labels-idx1-ubyte.gz
・t10k-images-idx3-ubyte.gz
ダウンロードしたファイルは.gz形式で圧縮されているので解凍してください。場合によっては解凍用のソフトが必要になるかもしれません。
私は作業用フォルダの中に「caffe」の他に「mnist」というフォルダを作成し、「mnist」フォルダの中に「data」フォルダを作成し、その中で解凍を行いました。
今回ダウンロードしたデータは、
・訓練用画像
・訓練用画像のラベル(訓練用画像が何番の画像かという正解を示すデータ)
・テスト画像
・テスト画像のラベル
の四つから成ります。
(3) LMDBの作成
次に、解凍したファイルからLMDBを作成します。
Caffeで訓練やテストを行う際には、LMDBかLevelDBと呼ばれるデータベース形式に変換する必要があります。
LMDBとLevelDBの違いについてはこの記事では触れませんが、今回はLMDBを使ってみることとしましょう。
caffe\binのフォルダの中に「convert_mnist_data.exe」というMNISTのファイルからLMDBを作成できる実行ファイルが存在するので、これを使ってみましょう。
MNIST以外に、一般の自分が用意した画像からLMDBを作成する場合には、同じフォルダにある「convert_imageset.exe」を使うことが多いです。
「convert_mnist_data.exe」はMNIST専用のコンバータと思っておけばよいでしょう。
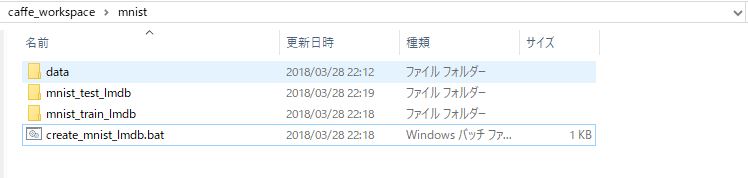
私はmnistフォルダの中に実行ファイルを叩くバッチを作り、それを叩いてLMDBを作成することとしました。
適当にテキストファイルなどを作り、そのファイル名を「create_mnist_lmdb.bat」に変更し、中身をメモ帳などで編集します。

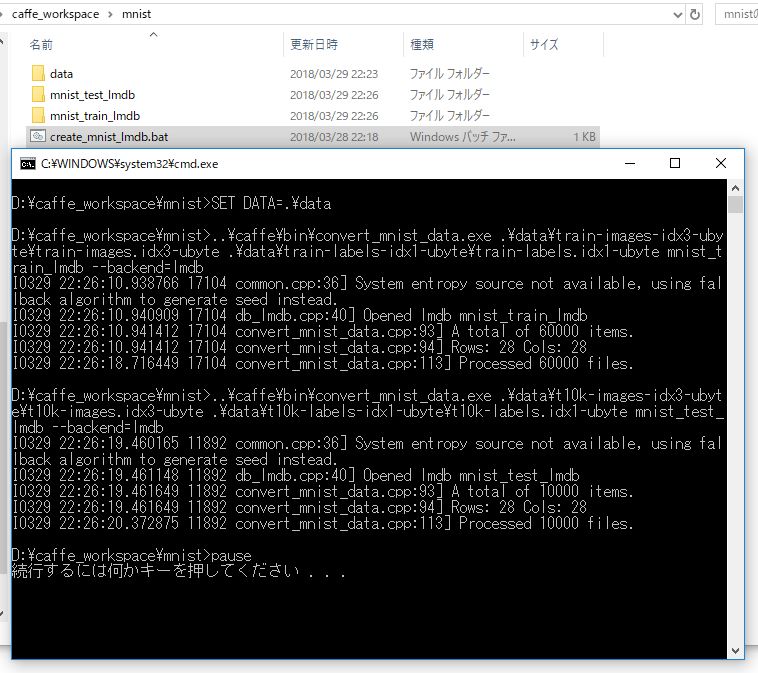
SET EXE=..\caffe\bin\convert_mnist_data.exe SET DATA=.\data %EXE% %DATA%\train-images-idx3-ubyte\train-images.idx3-ubyte %DATA%\train-labels-idx1-ubyte\train-labels.idx1-ubyte mnist_train_lmdb --backend=lmdb %EXE% %DATA%\t10k-images-idx3-ubyte\t10k-images.idx3-ubyte %DATA%\t10k-labels-idx1-ubyte\t10k-labels.idx1-ubyte mnist_test_lmdb --backend=lmdb pause
「mnist_train_lmdb」と「mnist_test_lmdb」がLMDBを保存するフォルダ名を表します。
このバッチをダブルクリックで実行すると、以下のように「mnist_train_lmdb」と「mnist_test_lmdb」というフォルダができていることがわかると思います。
これでLMDBの作成は完了しました。
(4) caffeで訓練
それでは、いよいよ訓練をしてみたいと思います。訓練に使うのは、「caffe\bin」のフォルダの中にある「caffe.exe」です。
訓練を行うためにはいくつかの設定ファイルが必要です。
これは、どのような設定や、どのような構造のニューラルネットワークを使ってMNISTの学習を行うかということを示す設定ファイルです。
今回は必要最低限なファイルとして、
<1> lenet_train_test.prototxt
<2> lenet_solver.prototxt
の二つを作ります。
それぞれのファイルは以下のURLのフォルダの中にあるので、それぞれダウンロードなり、中身をコピペして用意してください。
外部サイト:Windows Example MNIST(Github)
保存場所としてはmnistフォルダ内に「prototxt」というフォルダを作り、
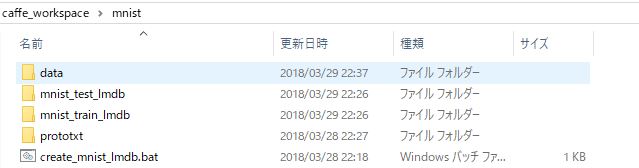
その中に二つのファイルを作成しました。それぞれのファイルについて、いくつか変更すべき箇所があるので注意してください。以下で説明します。
<1> lenet_train_test.prototxt
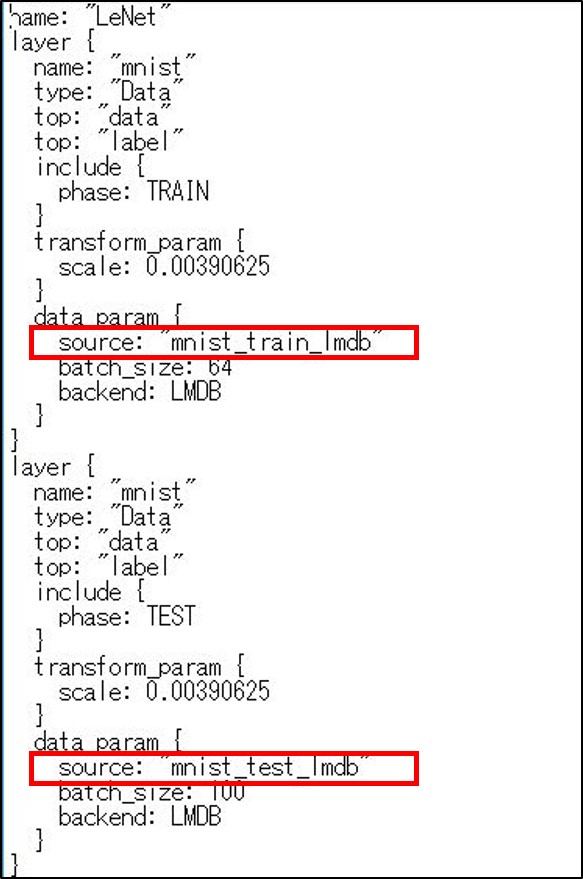
data_paramの中にあるsourceを、(2)で作成したLMDBのパスに合わせてください。私の場合はバッチのあるフォルダの直下にLMDBのフォルダを作成したので、訓練用が「mnist_train_lmdb」、テスト用が「mnist_test_lmdb」です。上が訓練の際に参照する画像、下が訓練中のテストに使用する画像へのパスになります。
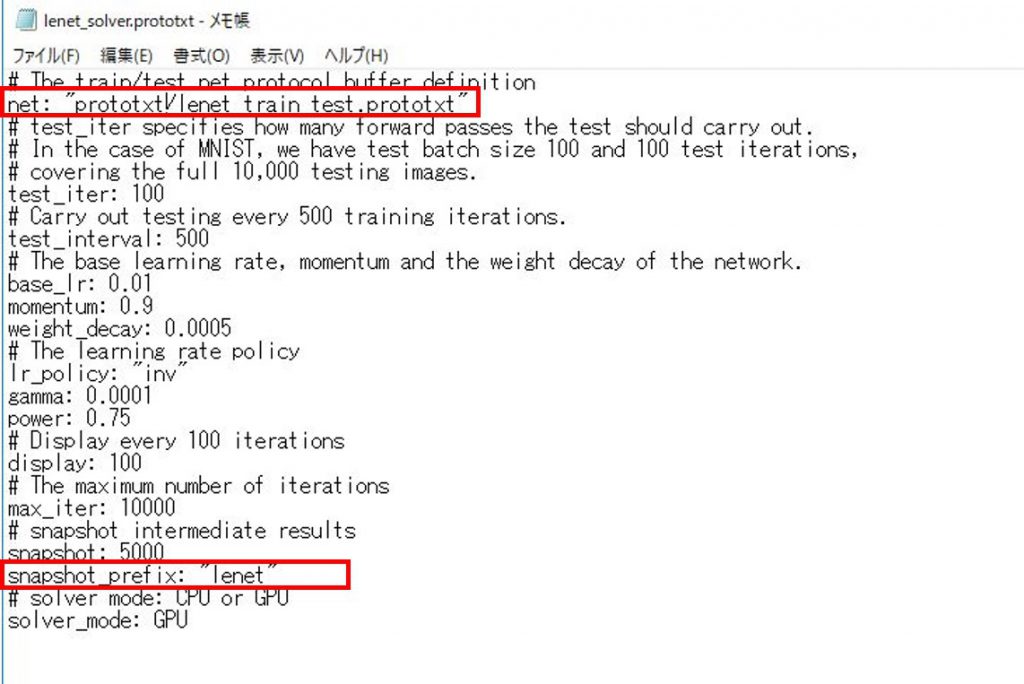
<2> lenet_solver.prototxt
変更箇所としてはこちらも2点となります。
まず、訓練とテスト用のモデルのネットワーク構成を読まないといけないため、「net:」のところを「lenet_train_test.prototxt」のパスに合わせる必要があります。
次に「snapshot_prefix:」の部分ですが、これは訓練中に、一定回数訓練が繰り返したときに途中経過のモデルを吐き出してくれる際のファイル名を示します。
デフォルトの設定だと”examples/mnist/lenet”が入っていて、そのようなフォルダはないと怒られてしまったので、仮置きで「lenet」としました。
二つのファイルを用意したら、いよいよ訓練を実行します。訓練用のバッチを作成しましょう。私は「mnist_train.bat」という名前で作成しました。
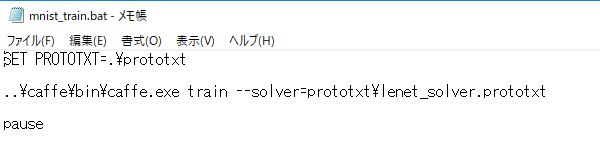
SET PROTOTXT=.\prototxt ..\caffe\bin\caffe.exe train --solver=prototxt\lenet_solver.prototxt pause
実行ファイル名の後に「train」を指定することで、テストではなく訓練であることを示します。また「–solver=」の後に、用意したsolverへのパスを指定します。
このバッチファイルをダブルクリックで実行すると、訓練が行われます。

右に表示されているlossの値が少しずつ小さくなっていけば、おそらく訓練は成功しているでしょう。
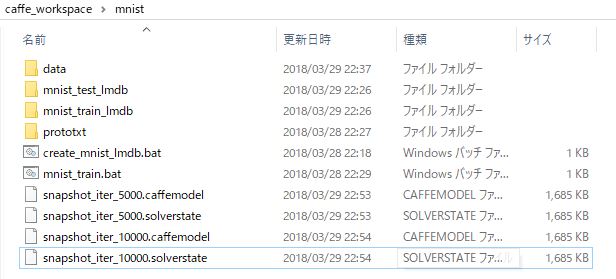
デフォルトの設定ではIterationが10000なので実行完了まで数分掛かるかもしれません。最後まで実行が完了すると学習の結果得られたモデルの正解率が表示されます。

また「snapshot_iter_10000.caffemodel」という名前で10000回回したときのモデルができていることが確認できると思います。
これにてモデルの作成は完了です。
まとめ
長くなってしまいましたが、今回はMNISTの学習をCaffeを使って行ってみました。
Tensorflowなどと異なり、既存のモデルや層の組み合わせであれば、プログラミングを行うことなく実行できてしまうのはCaffeの一つの特徴です。
次回は違うネットワークや自作画像での学習、実際に他のプログラムに組み込んで使う部分などをやってみたいですね。