本日ご紹介するのは、論文「Few-shot Novel View Synthesis using Depth Aware 3D Gaussian Splatting」です。
arXivリンク: https://arxiv.org/abs/2410.11080v1
Novel View Synthesis(新視点合成)とは?
Novel View Synthesis(NVS)とは、私たちが手持ちの数枚の写真から、まだ見たことのない角度からの画像を生成する技術のことです。例えば、お気に入りのカフェを数枚撮影するだけで、様々なアングルから見たカフェの様子をバーチャルに再現できる、といったイメージですね。
この技術は、AR/VR、自動運転、ロボティクスなど、幅広い分野での応用が期待されています。
従来の技術と「Few-shot」の課題
これまでのNVS研究では、NeRF(Neural Radiance Field)という技術が注目されてきました。NeRFは非常に高品質な画像を生成できる反面、計算コストが高く、レンダリングに時間がかかるという課題がありました。
そこに登場したのが、Kerblらが提案した3D Gaussian Splatting(3DGS)です。これは3Dのガウシアン(球状の点)を使ってシーンを表現し、高速かつ高品質なレンダリングを可能にしました。
しかし、これらの素晴らしい技術にも共通の課題があります。それは、「Few-shot」、つまり、ごく少数の入力画像しかない場合に、その性能が著しく低下してしまうことです。現実世界では、多くの視点からの画像を用意できない場面も多いため、この「Few-shot」問題は非常に重要です。
本研究は、このFew-shot Novel View Synthesisにおける3DGSの性能低下を解決するための一歩を踏み出しました。
Depth Aware 3DGSの画期的なアプローチ
研究チームは、このFew-shot問題に対して「Depth Aware 3D Gaussian Splatting」という新しい手法を提案しています。これは、深度情報(Depth)をうまく活用することで、少ない入力画像からでもシーンの3D形状を正確に学習し、高品質な新視点画像を生成することを可能にします。
一体どのような工夫が凝らされているのでしょうか?
1. 深度情報の活用で3D形状を制約
本研究の最も大きなポイントは、単眼深度推定(Monocular Depth Prediction)の情報を事前知識(prior)として利用する点です。これは、1枚の画像からそのシーンの各ピクセルまでの距離(深度)を推定する技術です。
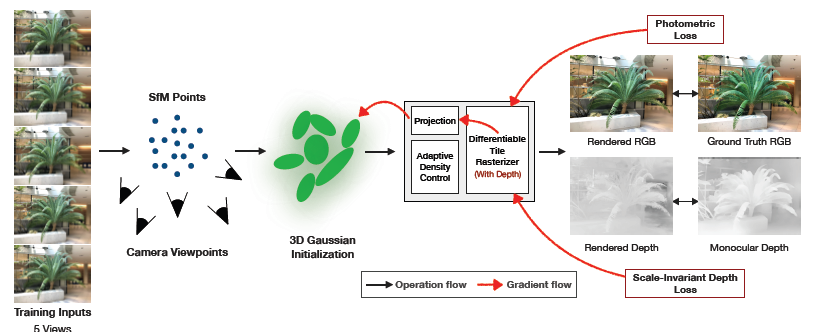
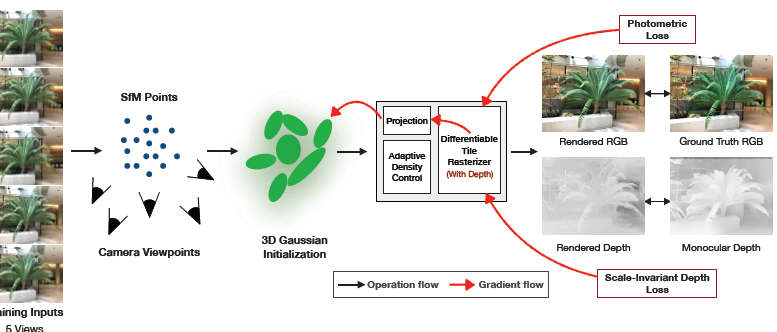
3DGSの学習プロセスにおいて、この推定された深度情報と、3DGS自身がレンダリングする深度マップを比較し、その差を損失として加えます。これにより、モデルはより正確な3D形状を学習するようになります。
さらに、深度のスケールが異なる問題を解決するため、スケール不変な深度損失(Scale-Invariant Depth Loss)を採用。これにより、単眼深度推定モデルの絶対的な深度値が多少異なっていても、モデルはシーンの相対的な形状を正しく捉えることができます。
2. 過学習を防ぐための色表現の工夫
少ない入力画像で多くの複雑な情報を学習しようとすると、往々にして過学習(Overfitting)が発生しやすくなります。モデルが訓練データに適合しすぎて、未知のデータに対してはうまく機能しなくなってしまう現象です。
3DGSでは、各ガウシアンの色を表現するために球面調和関数(Spherical Harmonics: SH)と呼ばれる数学的な関数を使います。高次のSHを使うと、より詳細で複雑な色を表現できますが、Few-shot設定ではこれが過学習の原因となる可能性があります。
そこで本研究では、SHの次数を「1」にまで減らすことで、色の表現をシンプルにし、過学習を防ぐ工夫をしています。これにより、少ない情報量でも安定してシーンの色を表現できるようになりました。
3. ガウシアンを「捨てない」戦略
オリジナルの3DGSでは、最適化の過程で不透明度(opacity)の低いガウシアン(スプラット)を定期的に削除する処理が行われます。これは、不要なガウシアンを減らして効率を高めるためのものですが、Few-shot設定では問題が発生します。
少ない入力ビューで初期化された点群は非常に疎なため、不透明度が低いという理由でガウシアンを削除してしまうと、シーンの多くの部分が失われ、再構成が不安定になったり、品質が低下したりします。
本研究では、この問題に対処するため、不透明度の低いスプラットを削除せずにすべて保持するというアプローチを採用しました。これにより、初期の疎な点群からでも、より安定してシーンを再構成できるようになります。

実験結果とその驚きの性能向上
研究チームは、LLFFデータセットを使用して提案手法を評価しました。わずか5枚の訓練画像から、3枚のテスト視点(補間視点と外挿視点を含む)を生成し、その品質を比較しています。

上の画像は、提案手法でレンダリングされた「Fern」シーンの新視点画像です。少ない入力ビューにもかかわらず、非常にリアルで詳細なシーンが再現されているのがわかります。特に、オリジナルの3DGSと比較すると、その品質の差は歴然です。
定量的な評価でも、PSNRで平均10.5%、SSIMで6.0%、LPIPSで14.1%もの大幅な改善を達成しました。これは、提案手法が画像をより忠実に再現し、構造的な類似性も高く、知覚的な品質も優れていることを示しています。
この品質向上は、より正確な3D形状を再構成できるようになったことに起因します。
これは提案手法によって生成された点群の視覚化です。オリジナル3DGSと比較して、よりクリーンでシャープな点群が形成されていることがわかります。深度情報を活用することで、シーンの構造をより正確に捉えられている証拠ですね。
特に注目すべきは、訓練時に提供されていない「外挿視点(extrapolated viewpoints)」でのPSNRが平均13.5%も向上したことです。これは、モデルが単に訓練画像に過学習するのではなく、シーンの真の3D形状を学習できていることを強く示唆しています。
まとめと今後の展望
本研究は、わずか5枚という少数の入力画像からでも、Depth Aware 3D Gaussian Splattingを用いることで、非常に高品質な新視点合成を実現しました。単眼深度推定を事前情報として活用し、過学習を防ぐための工夫を凝らすことで、これまでのFew-shot NVSの限界を大きく押し広げたと言えるでしょう。
もちろん、深度推定モデルの精度に依存するという限界や、非常に疎な入力ビューの場合の初期点群生成の課題など、今後の改善点も挙げられています。しかし、この研究はFew-shot Novel View Synthesisの分野に大きな進歩をもたらすものとして、今後の発展が非常に楽しみです。