
CUDAのプログラムを実行するにあたり、並列処理の数を決める「ブロック」「スレッド」の数を指定する必要があることを以前の記事で説明しました。
以下の図の通り、CUDAでは並列処理の実行前にブロック数Bと、(1ブロックあたりの)スレッド数Sを設定する必要があり、合計スレッド数はN=B×Sとなります。
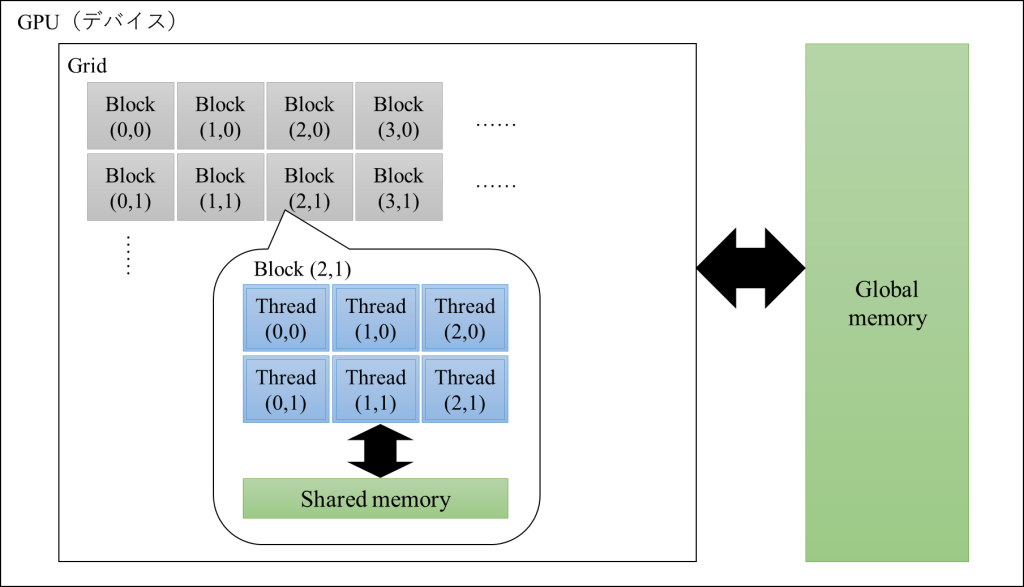
そのため、このCUDAプログラミングではブロック数Bと、(1ブロックあたりの)スレッド数Sを決めることが重要になってきますが、そもそもこの「(1ブロックあたりの)スレッド数S」には、そこまで大きい値を設定することはできず、この制約に基づきブロック数とスレッド数を指定することが多いです。
今回は、この1ブロックあたりの最大スレッド数はいくつまで設定できるのかということを説明します。
1ブロックあたりの最大スレッド数Sはいくつか?
インターネットで検索すると、1ブロックあたりの最大のスレッド数は「512」と紹介している場合もあれば、「1024」と紹介されている場合もあります。
これは、正確には使っているGPUのアーキテクチャ等によるため「512」の場合もあれば、「1024」の場合もあります。
ただし感覚的には、比較的新しいGPUで開発されている方は「1024」である場合が多いようです。
ただ、この点はしっかりと確認をしておかないと、想定外の動作をすることがあるので注意が必要です。
最大スレッド数Sを確認する方法
CUDAをインストールしている環境であれば、以下のコードを実行することで確認できます。
#include <iostream>
#include <cuda_runtime.h>
int main()
{
// Confirming cuda device property
cudaDeviceProp dProp;
cudaGetDeviceProperties(&dProp, 0);
std::cout << "Device: " << dProp.name << std::endl;
std::cout << "Maximum number of threads per block:" << dProp.maxThreadsPerBlock << std::endl;
std::cout << "Max dimension size of a thread block (x,y,z): (" << dProp.maxThreadsDim[0] << ","
<< dProp.maxThreadsDim[1] << "," << dProp.maxThreadsDim[2] << ")"<< std::endl;
std::cout << "Max dimension size of a grid size (x,y,z): (" << dProp.maxGridSize[0] << ","
<< dProp.maxGridSize[1] << "," << dProp.maxGridSize[2] << ")" << std::endl;
return 0;
}「cudaGetDeviceProperties」というCUDA関連の情報を取得できるプロパティを用いることで、現在使っている環境の情報を知ることができます。
私の環境で実行すると、以下の結果となりました。

特に重要なのは2行目の「Maximum number of threads per block:」で、これが1ブロックあたりに設定できる最大のスレッド数です。今回は「1024」になっていることがわかります。
3行目「Max dimension size of a thread block (x,y,z):」については、CUDAでGPUで並列処理するときに、1ブロックあたりのスレッド数を3次元で指定することができますが、そのときの各次元に設定できる最大値のようです。
おそらくですが、並列処理を実行する際にはx×y×zが最大スレッド数1024を下回らなければならず、あくまでxは1024が最大、yは1024が最大、zは64までしか指定できないということを言っていると思います。1024×1024×64個のスレッドを1ブロックに指定することはできません。
4行目はスレッドではなくブロックの最大数のようです。こちらはかなり最大が大きく設定されているので、この制約に引っかかることは少なそうに感じますね。
ブロック数とスレッド数の決定方法
一概には言えませんが、決め方の一つとして、1ブロックあたりのスレッド数Sは最大値に設定して、ブロック数は並列処理したい数と、スレッド数Sから決定する方法がよく使われるようです。
つまり、並列処理の数N=65536であれば、1ブロックあたりのスレッド数Sは最大のS=1024に設定し、ブロック数はN/S=65536/1024 = 64のように決定します。
スレッド数の最大を超えたスレッド数を指定した場合に何が起こるのか
以下のプログラムで実験しました。
このプログラムでは乱数をN=32×1024個作成し、N並列で各乱数r[i]に対してsin(r[i])*sin(r[i]) + cos(r[i])*cos(r[i])をGPU側で計算します。
sin(r[i])*sin(r[i]) + cos(r[i])*cos(r[i])は乱数の値に関わらず計算値は1になりますから、GPU側で計算した結果は全て1になり、最後に配列の総和を計算すると1がN個ありますからN=32×1024=32768となります。
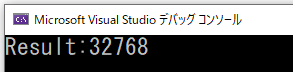
すなわち、コンソールに「32768」と表示されるのが想定動作です。
#include <iostream>
#include <cuda_runtime.h>
__global__ void gpu_function(float* d_x, float* d_y)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
d_y[i] = sin(d_x[i]) * sin(d_x[i]) + cos(d_x[i]) * cos(d_x[i]);
}
int main()
{
int N = 32 * 1024;
float* host_x, * host_y, * dev_x, * dev_y;
host_x = (float*)malloc(N * sizeof(float));
host_y = (float*)malloc(N * sizeof(float));
// Creating random numbers
for (int i = 0; i < N; i++) {
host_x[i] = rand();
}
// Data transfer from CPU to GPU
cudaMalloc(&dev_x, N * sizeof(float));
cudaMalloc(&dev_y, N * sizeof(float));
cudaMemcpy(dev_x, host_x, N * sizeof(float), cudaMemcpyHostToDevice);
// Parallel processing in GPU
// gpu_function <<< 64, 512 >> > (dev_x, dev_y);
gpu_function <<< 32, 1024 >> > (dev_x, dev_y);
//gpu_function <<< 16, 2048 >> > (dev_x, dev_y);
int end = clock();
// Data transfer from GPU to CPU
cudaMemcpy(host_y, dev_y, N * sizeof(float), cudaMemcpyDeviceToHost);
// Confirmation of the results
float sum = 0.0f;
for (int j = 0; j < N; j++) {
sum += host_y[j];
}
std::cout << "Result:" << sum << std::endl;
return 0;
}注目すべきは28~30行目で、3種類のブロック数Bとスレッド数Sを用意し、1つを実行、2つはコメントアウトしています。
29行目にB=32、N=1024のケースを記述していますが、これを実行すると以下の結果になりました。想定動作であることがわかります。
次に30行目のコメントアウトを外し、29行目をコメントアウトしてB=16、N=2048を実行してみると、以下の結果となります。
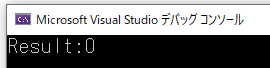
結果が0になってしまい、想定動作ではないことがわかります。
経験的には、スレッド数について指定可能な最大数を上回るように設定した場合、処理が実施されず初期値(大体0)がそのまま返ってきてしまうようです。
エラーが出ずに単にゼロが返ってきてしまい、原因に悩むケースがあるので、動作を知っておきましょう。