「DINOv2: Learning Robust Visual Features without Supervision」
本論文は、2024年1月にTransactions on Machine Learning Researchで発表されました。
近年、自然言語処理(NLP)の分野では、大量のデータで事前学習された「Foundation Model(基盤モデル)」が目覚ましい進歩を遂げています。これらのモデルは、特定タスク向けのファインチューニングなしで、そのまま(”out-of-the-box”)様々なタスクに対応できる汎用性の高さが特徴です。
このような成功を受け、画像認識の分野でも同様の汎用Foundation Modelの登場が期待されていました。今回ご紹介する「DINOv2」は、自己教師あり学習(Self-Supervised Learning, SSL)というアプローチを用いて、この期待に応える画期的なビジュアル特徴学習モデルです。
自己教師あり学習(SSL)とは?
従来の機械学習では、画像に「これは犬」「これは車」といったラベルを手作業で付与し、そのラベルを使ってモデルを学習させる「教師あり学習」が主流でした。しかし、大量の画像にラベルを付ける作業は膨大な時間とコストがかかります。
そこで登場したのが「自己教師あり学習(SSL)」です。
SSLでは、画像自体が持つ情報を利用して、ラベルなしでモデルを学習させます。例えば、画像の一部を隠して残りの部分から隠された部分を予測させたり、画像の異なる部分が同じオブジェクトを表すように学習させたりします。これにより、モデルは汎用的な「ビジュアル特徴」を自律的に学習できるようになります。
DINOv2が目指す「真の汎用性」
これまでのSSL研究の多くは、小規模なキュレートされたデータセット(ImageNet-1kなど)や、品質が低い非キュレートな大規模データセットで行われてきました。
しかし、DINOv2の論文では「十分な量のキュレートされた多様なデータ」で学習すれば、既存のSSL手法でも非常にロバストな汎用ビジュアル特徴を生成できることを示しています。
DINOv2は、画像分類のような「画像全体」を理解するタスクから、セグメンテーションや深度推定のような「ピクセルレベル」で画像を理解するタスクまで、幅広く対応できる「out-of-the-box」な特徴を目標としました。
DINOv2の革新的なアプローチ
DINOv2は、既存のDINOやiBOTといった自己教師あり学習手法をベースにしつつ、以下の主要な技術革新と組み合わせることで、その性能を飛躍的に向上させました。
1. 大規模かつ高品質なデータセット「LVD-142M」の構築
DINOv2の成功の鍵の一つは、1億4200万枚にも及ぶ大規模で多様な「キュレートされた画像データセット(LVD-142M)」を自動的に構築した点です。
これは、非キュレートなウェブ画像から、キュレートされた高品質な画像に近いものを自動で選別・収集するパイプラインを開発することで実現されました。
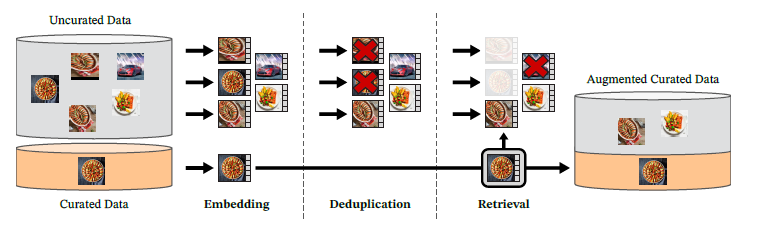
このアプローチは、NLPにおけるテキストデータの前処理パイプラインからインスピレーションを得たものです。データの品質と多様性を高めることで、モデルの汎化能力が大幅に向上しました。

この図では、PCA(主成分分析)を用いて、DINOv2が画像からどのような特徴を学習しているかを可視化しています。
同じ列の画像は同じカテゴリに属し、そのパッチ(小さな領域)のPCAコンポーネントを色で表現しています。
背景が除去され、オブジェクトの主要な部分が分離され、さらに同じオブジェクトの異なるポーズやスタイル、さらには異なるオブジェクト間でも意味的に対応するパーツが同じ色で表現されていることが分かります。これは、DINOv2がオブジェクトの「部分」を理解し、その特徴が非常に汎用的であることを示しています。
2. 学習手法と効率の向上
DINOv2は、DINOとiBOTのロス関数を組み合わせ、さらにSwAVのセンタリング、特徴を均一に分散させるKoLeo正則化などを取り入れています。
さらに、大規模モデルと大規模データの学習を高速化・安定化させるための効率的な実装も重要です。FlashAttentionによるメモリ効率の良いAttention機構、複数のシーケンスをまとめて処理するSequence Packing、大規模モデルの学習に必要なFSDP(Fully-Sharded Data Parallel)など、様々な最新技術が活用されています。
3. 知識蒸留による小規模モデルの高性能化
最大10億パラメータの巨大なViT-gモデルを学習した後、その知識をより小さなモデル(ViT-S, ViT-B, ViT-L)に「蒸留」するプロセスも採用しています。これにより、小規模なモデルでも、ゼロから学習するよりもはるかに優れた性能を発揮できるようになりました。
DINOv2の驚異的な性能
DINOv2は、多岐にわたるコンピュータービジョンタスクにおいて、その性能を実証しました。特に注目すべきは、ファインチューニングなしで、従来の自己教師あり学習モデルを大幅に上回り、OpenCLIPなどの弱教師あり学習モデル(テキスト情報も利用)と同等、あるいはそれ以上の性能を達成している点です。
- 画像分類: ImageNet-1k、iNaturalist、Places205などのデータセットで高い精度を記録。特にiNaturalistのようなきめ細かい分類タスクでOpenCLIPを大きく上回る性能を示しました。
- 密な予測タスク(セグメンテーション、深度推定): ADE20kやKITTIなどのデータセットで、DINOv2のパッチレベル特徴が非常に高品質であることを示しました。複雑なシーンにおけるセマンティックセグメンテーションや、物体の深度推定において、他のモデルよりもはるかに滑らかで正確な結果を生成します。

この図は、セマンティックセグメンテーション(ADE20K)と深度推定(NYUd, SUN RGB-D, KITTI)の定性的な結果を、OpenCLIP-GとDINOv2-gで比較したものです。
DINOv2は、線形分類器を使用しているにもかかわらず、OpenCLIPよりもはるかに高品質で滑らかなセグメンテーションマスクと深度マップを生成していることが分かります。これはDINOv2のパッチレベル特徴が非常に優れていることを示しています。
- インスタンス認識: OxfordやParisなどのランドマーク認識タスクで、自己教師あり学習モデルとして過去最高の性能を記録し、弱教師あり学習モデルも凌駕しました。
- 領域の理解と汎化能力: DINOv2が学習した特徴は、異なるドメインの画像(写真と絵、実写と3Dモデルなど)や、異なるポーズのオブジェクト間でも、意味的に関連する領域を正確にマッチングできる能力を示しています。

この図は、異なる画像間でパッチレベルの特徴をマッチングさせた結果を示しています。DINOv2は、航空機と鳥の翼、象の異なるポーズ、あるいは車の絵と実際の車のように、意味的に類似した領域を正確に対応付けることができます。これは、DINOv2の学習した特徴がスタイルやポーズの変化に強く、高度な意味的理解を持っていることを視覚的に示しており、モデルの優れた汎化能力を強調しています。
まとめと今後の展望
DINOv2は、大規模なキュレートされたデータセットと、既存のSSL手法の組み合わせ、そして効率的な実装によって、ファインチューニングなしで使える強力な汎用ビジュアル特徴を生み出しました。
このモデルの登場は、NLPのFoundation Modelのように、様々なコンピュータービジョンタスクにおいて「out-of-the-box」で高性能を発揮する「視覚のFoundation Model」の実現に向けた大きな一歩と言えるでしょう。今後は、このようなビジュアル特徴と言語モデルを組み合わせることで、より高度な言語対応AIシステムの実現が期待されています。