
大規模なAIモデルが次々と発表される中、DeepMindが発表した「Flamingo」というVisual Language Model(VLM)は、特にFew-Shot学習の分野で注目を集めています。
この論文「Flamingo: a Visual Language Model for Few-Shot Learning」は、NeurIPS 2022で発表され、arXiv:2204.14198v2でも公開されています。
今回は、このFlamingoがどのような技術で、なぜFew-Shot学習において画期的な成果を上げたのかを初心者にも分かりやすく解説します。
Few-Shot学習の重要性とは?
AIモデルを開発する際、通常は非常に多くのデータを使ってモデルを学習させ、特定のタスク向けに「ファインチューニング」という追加学習を行うのが一般的です。
しかし、この方法だと、新しいタスクが登場するたびに大量のデータを用意し、計算リソースを費やしてファインチューニングを繰り返す必要がありました。
Few-Shot学習は、わずかな(数個から数十個の)データ例を提示するだけで、新しいタスクに迅速に適応できる能力を指します。人間が数例を見れば新しい概念を理解できるように、AIも少ない情報から効率的に学習できれば、より汎用性が高く、現実世界で応用しやすいモデルが実現します。
Flamingoは、このFew-Shot学習において、画像や動画とテキストを組み合わせたマルチモーダルなタスクで、これまでのState-of-the-Art(SOTA)を大きく塗り替える成果を達成しました。

(論文”Flamingo: a Visual Language Model for Few-Shot Learning”より引用)
Flamingoのアーキテクチャの秘密
Flamingoの最大の魅力は、既存の強力な「Vision-onlyモデル」(画像や動画の理解に特化したモデル)と「Language-onlyモデル」(テキストの理解と生成に特化したモデル)を、賢く組み合わせている点にあります。
モデルの核となるのは、以下の二つの革新的なアーキテクチャコンポーネントです。
- Perceiver Resampler
これは、Vision Encoder(視覚情報を抽出する部分)から得られる可変サイズ(様々な大きさ)の画像や動画の特徴を、固定された少ない数の「ビジュアルトークン」に変換するモジュールです。これにより、モデルは入力される画像や動画の解像度やフレーム数によらず、効率的に視覚情報を処理できるようになります。 - GATED XATTN-DENSEレイヤー
Flamingoは、事前に学習済みの巨大な言語モデルを「凍結」して利用します。これにより、言語モデルが持つ豊富な知識を失うことなく活用できます。GATED XATTN-DENSEレイヤーは、この凍結された言語モデルの各層の間に挿入され、Vision Encoderから得られたビジュアルトークンと言語モデルのテキスト表現を組み合わせる役割を担います。
この層は初期化時に出力が0になるようなゲート機構を持っており、これにより学習の安定性が向上し、性能を高めることに貢献しています。
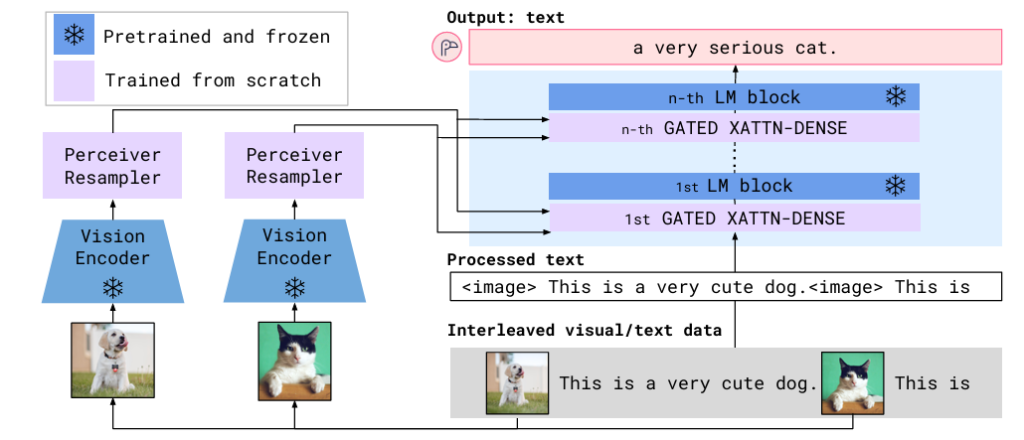
(論文”Flamingo: a Visual Language Model for Few-Shot Learning”より引用)
大規模なマルチモーダルデータでの学習
Few-Shot学習で高い性能を出すためには、多様な状況で視覚とテキストがどのように関連するかをモデルが深く理解している必要があります。Flamingoは、このために「M3W (MultiModal MassiveWeb)」という独自のデータセットを含む、様々なマルチモーダルデータで学習されました。
M3Wは、Webページから抽出されたテキストと画像が任意に混在するデータセットです。これに加えて、画像とテキストのペア、動画とテキストのペアからなる大規模なデータセットも利用しています。
これらの多様な形式のデータで学習することで、Flamingoは画像や動画の内容をテキストで説明したり、テキストによる質問に画像の内容に基づいて答えたりする能力を身につけています。訓練時に扱った画像数を超えて、推論時に最大32枚の画像や動画の情報を活用できる柔軟性も持っています。
Flamingoの驚くべき性能と応用例
Flamingoは、画像キャプション生成、視覚的質問応答(VQA)、動画タスクなど、16種類の多様なマルチモーダルタスクにおいて、Few-Shot学習で新たなSotAを達成しました。
驚くべきことに、一部のタスクでは、わずか32例という極めて少ないタスク固有のデータしか使わずに、数千倍ものデータでファインチューニングされた既存のSotAモデルの性能を上回る結果を出しています。モデルのサイズが大きいほど、またFew-Shotのサンプル数が多いほど、性能が向上するという大規模言語モデルと同様の傾向も確認されています。
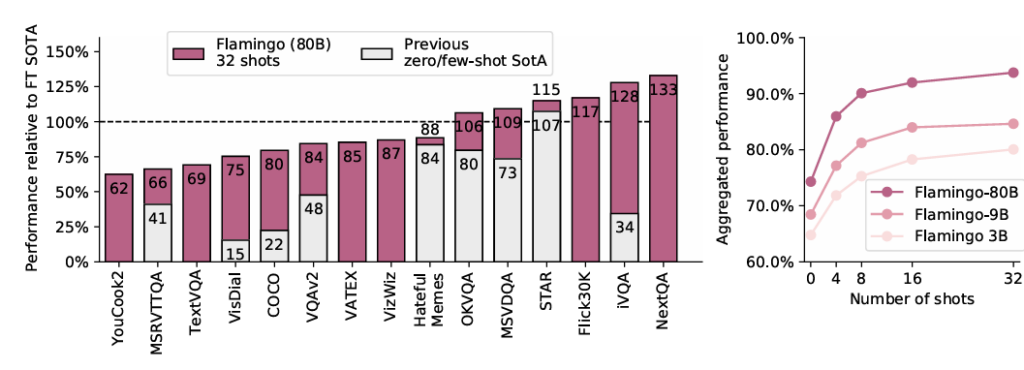
Flamingoは、例えば以下のような多様なタスクでその能力を発揮します。
- 視覚的質問応答 (VQA): 画像を見て質問に答える。
- 画像/動画キャプション生成: 画像や動画の内容を説明するテキストを生成する。
- マルチモーダル対話: 画像を提示しながら、モデルと自然な会話を行う。
- Few-Shot分類: わずかな例で新しいカテゴリのオブジェクトを分類する。
まとめ
Flamingoは、Vision-onlyモデルと言語モデルを統合し、Few-Shot学習という新たな地平を切り開いた画期的なモデルです。その能力は、少ないデータで多様なタスクに迅速に適応できるという点で、今後のAIの汎用性向上に大きく貢献すると期待されています。
ただし、大規模な言語モデルが持つハルシネーション(誤った情報を生成する現象)や、学習データに起因する社会的バイアスといった課題も継承しています。これらの課題に対する研究や、モデルのさらなる性能向上に向けた取り組みが、今後の重要な研究テーマとなるでしょう。