本記事では、2019年にarXivで公開された論文「VISUAL BERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE」で提案されている「VisualBERT」というモデルについて、初心者にも分かりやすく解説します。
論文リンク: arXiv:1908.03557v1
画像とテキストを同時に理解する難しさ
近年、AI技術の発展により、画像認識や自然言語処理の分野で目覚ましい進歩が見られます。しかし、「画像に何が写っているか」と「それがテキストでどう表現されているか」という両方を同時に、かつ深く理解するタスクは、いまだに多くの課題を抱えています。
例えば、画像内のオブジェクトを認識するだけでなく、「なぜこの人はこんな行動をしているのか?」「画像と質問文が指すものは何か?」といった、より高度な推論が求められるタスクです。
この複雑な問題を解決するために、VisualBERTは自然言語処理で大きな成功を収めた「BERT」というモデルをベースに、画像とテキストの情報を効率的に統合する新しいアプローチを提案しました。
VisualBERTの核となるアイデア
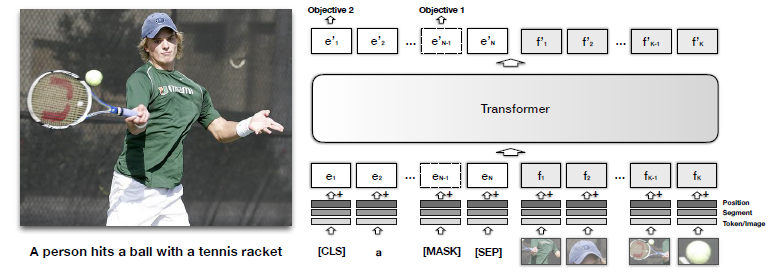
VisualBERTの核となるアイデアは、BERTの強力なTransformerアーキテクチャを、テキストだけでなく画像データにも適用するというものです。BERTはテキストの単語間の関係性を「Attention」という仕組みで学習しますが、VisualBERTではこのAttentionメカニズムを使って、単語と画像領域間の関係性も学習させます。
具体的には、画像から検出されたオブジェクトの領域(バウンディングボックス)を、テキストの単語と同じように「視覚トークン」として扱います。これらの視覚トークンとテキストトークンは、同じTransformerレイヤーにまとめて入力されます。
これにより、モデルはテキストと画像の両方から情報を得て、互いの文脈を理解しながら、より豊かな表現を学習できるようになります。
VisualBERTのアーキテクチャ
VisualBERTは、基本的にBERTの多層Transformerを基盤としています。BERTが単語の埋め込み表現(token embedding、segment embedding、position embedding)を入力として受け取るのと同じように、VisualBERTもテキストの埋め込み表現と、画像の特徴を表す視覚的な埋め込み表現を生成します。
視覚的な埋め込み表現は、画像内の各オブジェクト領域から抽出された特徴(fo)、それが画像からのものであることを示すsegment embedding(fs)、そしてアライメント情報を示すposition embedding(fp)を組み合わせて作られます。
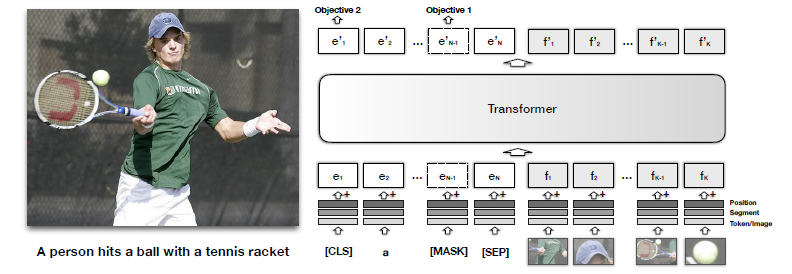
これらのテキストと画像由来の埋め込みが、Transformerの複数の層を通じて一緒に処理されます。これにより、モデルはテキストと画像の間で暗黙的なアライメントを発見し、単一の統合された表現を構築できるのです。
Visually-Groundedな事前学習
VisualBERTの性能を最大限に引き出すためには、BERTと同様に「事前学習」が非常に重要です。VisualBERTでは、特に画像キャプションデータセットであるCOCOを用いて、以下2つの視覚的に根ざした(visually-grounded)言語モデルの目的で事前学習を行います。
- マスク言語モデリング(Masked language modeling with the image): テキスト入力の一部をマスクし、残りのテキストと画像情報に基づいてマスクされた単語を予測するように学習します。画像情報があることで、より正確な単語の予測が可能になります。
- 文章-画像予測(Sentence-image prediction): 与えられたテキストが画像と一致するかどうかを判断するようにモデルを訓練します。これにより、モデルはテキストと画像間の意味的な整合性を学習します。
これらの事前学習を通じて、VisualBERTはテキストと画像の両方から転移可能な表現を学習し、多様なVision-and-Languageタスクで高い性能を発揮できるようになるのです。
驚くべき実験結果
VisualBERTは、VQA(Visual Question Answering)、VCR(Visual Commonsense Reasoning)、NLVR2(Natural Language for Visual Reasoning)、Flickr30K(Region-to-Phrase Grounding)といった、様々なVision-and-Languageタスクで広範な実験が行われました。
その結果、VisualBERTは既存の最先端モデルに匹敵するか、あるいは上回る性能を達成しました。特筆すべきは、そのシンプルさにも関わらず、これらの複雑なタスクで高い性能を出している点です。事前学習の有無による比較(Ablation Study)では、COCOデータセットでの事前学習がモデルの性能に大きく貢献していることが示されています。
VisualBERTは「何を見ているのか」?
VisualBERTのAttentionメカニズムを解析することで、モデルが単語と画像領域をどのように紐付けているかを垣間見ることができます。論文では、明示的な「単語と画像領域のアライメント」に関する教師なしにも関わらず、Attentionヘッドがエンティティグラウンディング(単語が対応する画像領域を特定すること)を正確に行っていることが示されています。
特に、Transformerの高層レイヤーになるほど、グラウンディングの精度が向上する傾向が見られます。これは、モデルが複数の層を通じて、テキストと画像の関係性を徐々に洗練させていくことを意味します。
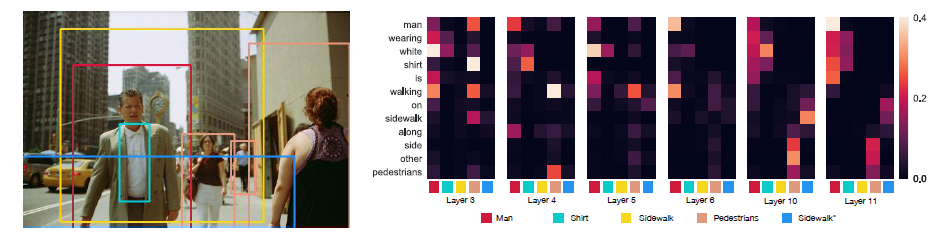
この画像は、VisualBERTのAttentionが「Man(男性)」「Shirt(シャツ)」「Sidewalk(歩道)」といった単語を、画像内の対応する領域にどのようにアラインメントしているかを示しています。特に、「walking」という動詞が、画像内の「man」の領域にアラインメントされている例は、モデルが構文的な関係性も捉えていることを示唆しています。
さらに、複雑な状況でのアライメントの洗練も観察されています。例えば、以下の画像では、初期の層では「husband(夫)」と「woman(女性)」の両方が同じ女性の領域にAttentionを向けていますが、高層になるにつれて、男性と女性が適切に分離され、それぞれの単語が正しい人物にアラインメントされるようになります。
このように、VisualBERTは単語と画像領域間のグラウンディングだけでなく、動詞とその引数の関係性など、より詳細な構文的関係も暗黙的に、かつ教師なしで学習できることが示されています。
まとめ
VisualBERTは、BERTのTransformerアーキテクチャを巧みに拡張し、画像とテキストの情報をシンプルかつ効果的に統合するモデルです。COCOデータセットを用いた視覚的に根ざした事前学習と、テキスト・視覚トークンを一緒に処理するAttentionメカニズムにより、多様なVision-and-Languageタスクで高い性能を発揮します。
また、モデル内部のAttentionメカニズムを解析することで、単語と画像領域の間の深い関係性や、構文的依存関係までもが学習されていることが明らかになり、その解釈性も注目に値します。