本日ご紹介するのは、Alibaba GroupのQwen Teamが発表した論文「Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution」です。
この研究は、LLM(大規模言語モデル)の進化系であるVLMの新たな可能性を切り開くもので、特に「任意の解像度で画像を処理できる」という点が大きな注目を集めています。
arXivのリンクはこちらです: https://arxiv.org/abs/2409.12191
はじめに:進化するAIと既存モデルの課題
近年、AI技術は目覚ましい進化を遂げ、テキストだけでなく画像や動画も理解できるLVLMが登場しました。これらは私たちの生活に深く浸透し、様々な場面で活用されています。
しかし、従来のLVLMにはいくつかの課題がありました。その一つが「固定された画像入力サイズ」です。多くのモデルは、画像を特定の解像度(例えば224×224ピクセル)に変換して処理するため、高解像度画像の詳細な情報が失われたり、人間の視覚が持つ「スケールや詳細に対する感度」を再現できなかったりしていました。
また、視覚情報を処理するVision Encoder部分が固定されている場合が多く、複雑な推論や微細なディテールを捉えるのに十分ではないという懸念もありました。さらに、動画のような動的なコンテンツを扱う際の、時間や空間の情報を効果的に表現する方法も模索されていました。
Qwen2-VLとは?新たなLVLMシリーズの登場
このような課題に対し、Qwen TeamはQwen2-VLシリーズを発表しました。これは、2B、8B、72Bという3つの異なるサイズのオープンウェイトモデルで構成されており、幅広い能力と最先端のパフォーマンスを誇ります。
特に、72Bモデルは、GPT-4oやClaude3.5-Sonnetといった商用モデルに匹敵する、あるいはそれ以上の性能を多くのマルチモーダルベンチマークで達成しています。その多様な能力は、以下のイメージで示されています。

このモデルは、画像や動画の理解、多言語OCR、数学的推論、さらにはデバイス操作を行うエージェントとしての能力まで、多岐にわたるタスクに対応できる汎用性を持っています。
Qwen2-VLの主要な技術革新
Qwen2-VLを特徴づける二つの重要な技術革新があります。
任意の解像度に対応する「Naive Dynamic Resolution」
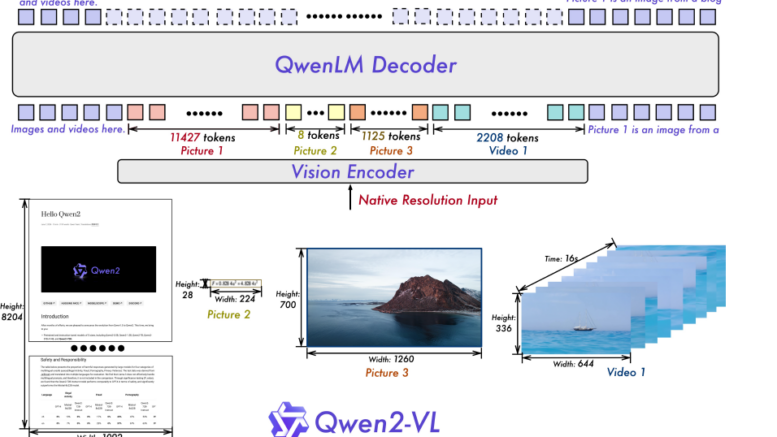
Qwen2-VLの最も画期的な点の一つは、「Naive Dynamic Resolution」メカニズムです。これにより、モデルは任意の解像度の画像を動的に処理し、可変数のビジュアルトークンに変換できるようになりました。
従来のモデルでは、画像を固定サイズにリサイズする必要がありましたが、Qwen2-VLでは元々の解像度に近い形で情報を保持できます。これにより、高解像度画像に含まれる微細なディテールも効果的に捉えることが可能になり、人間の視覚に近い感覚での世界認識を実現しています。
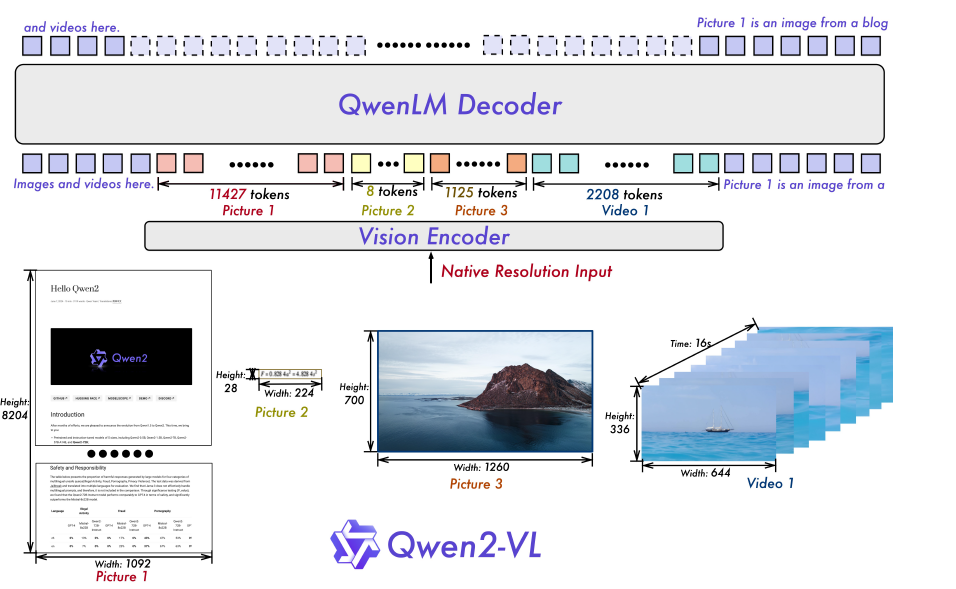
この技術は、Vision Transformer (ViT) から従来の絶対位置埋め込みを削除し、代わりに2D-RoPE(Rotary Position Embedding)を導入することで実現されています。これにより、モデルは画像の2次元的な位置情報をより柔軟に扱えるようになりました。
マルチモーダル情報統合の鍵「M-RoPE」
もう一つの重要な技術は「Multimodal Rotary Position Embedding (M-RoPE)」です。LLMで一般的に使われる1D-RoPEは1次元の位置情報に特化していますが、M-RoPEはこれを拡張し、時間、高さ、幅という3つのコンポーネントに分解して位置情報をモデル化します。
これにより、テキスト、画像、動画といった異なるモダリティ間で、時間的・空間的な位置情報を効果的に融合できるようになりました。例えば、動画の場合、フレームごとに時間IDが増分され、画像の場合には高さと幅のIDが割り当てられます。このアプローチにより、モデルは動画のような動的なコンテンツを自然に理解できるようになるだけでなく、トレーニング時に与えられたよりも長いシーケンス(文章や動画の長さ)に対しても、高い外挿能力を発揮します。
画像と動画の統一的な理解
Qwen2-VLは、画像と動画を統一的なパラダイムで処理します。これは、画像データと動画データを混ぜたトレーニングを行うことで実現されました。動画は毎秒2フレームでサンプリングされ、3D畳み込みを導入することで、2Dのパッチではなく3Dのチューブとして処理されます。これにより、シーケンス長を増やさずに、より多くの動画フレームを処理できるようになっています。
このような統一的なアプローチは、モデルが現実世界の複雑な動的な性質をより深く理解する上で非常に重要です。
Qwen2-VLの驚くべき能力
Qwen2-VLは、これらの技術革新により、多岐にわたるタスクで優れた性能を発揮します。
幅広いタスクでSoTA級の性能
DocVQA(文書QA)、InfoVQA(情報グラフィックQA)、RealWorldQA(実世界QA)、MTVQA(多言語動画QA)、MathVista(数学的推論)など、多くのベンチマークで高い競争力を示し、既存のモデルを凌駕する結果を出しています。特に、多言語OCRや文書理解のタスクで顕著な強みを見せています。
例として、様々な色や数字が書かれたブロックの画像から、その配置と色、数字を正確に認識・記述する能力は、Qwen2-VLの基本的な視覚認識能力の高さを示しています。
多言語OCRと数学的推論
Qwen2-VLは、多言語テキスト認識と理解においても際立っています。英語や中国語だけでなく、ヨーロッパの主要言語、日本語、韓国語、アラビア語、ベトナム語など、様々な言語の画像内テキストを高い精度で認識・理解できます。さらに、MathVistaやMathVisionといったベンチマークで示されるように、視覚情報を含む複雑な数学問題の推論能力も非常に高いです。
長尺動画の理解とエージェント機能
20分以上の長尺動画を理解し、それに基づいた質問応答や対話、コンテンツ作成が可能です。これは、M-RoPEによる長尺シーケンス対応能力の恩恵が大きいと言えます。また、高度な推論と意思決定能力により、スマートフォンやロボットといったデバイスと連携し、視覚入力とテキスト指示に基づいて自律的に操作するエージェントとしても機能する潜在力を持っています。
まとめ
Qwen2-VLシリーズは、その革新的な「Naive Dynamic Resolution」と「M-RoPE」により、任意の解像度の画像や長尺の動画を含む、多様なマルチモーダル情報をこれまでにない精度と効率で理解できるVLMです。
2B、8B、72Bというオープンウェイトモデルは、GPT-4oやClaude3.5-Sonnetといった最先端の商用モデルに匹敵する性能を誇り、多言語対応、エージェント機能など、幅広い実世界タスクでの応用が期待されます。