今回ご紹介するのは、リアルタイム物体検出の分野で新たなState-of-the-Art(SOTA)を打ち立てた「YOLOv7」に関する論文です。
論文名: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
arXivリンク: https://arxiv.org/abs/2207.02696
著者: Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao
所属: Institute of Information Science, Academia Sinica, Taiwan
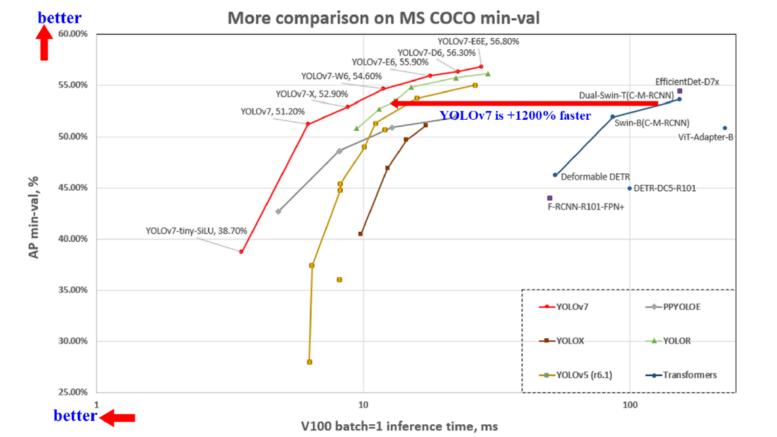
YOLOv7は、V100 GPU上で5 FPSから160 FPSの幅広い速度帯で、既存のすべての物体検出器を速度と精度の両方で上回るという、驚くべき性能を達成しました。
特に30FPS以上では、56.8% APという最高の精度を誇ります。
特筆すべきは、YOLOv7がMS COCOデータセットのみを使って、ゼロから学習されている点です。追加のデータセットや事前学習済みの重みを一切使用していません。
研究の成果はGitHubで公開されており、誰でもその強力な性能を体験できます。
ソースコード: https://github.com/WongKinYiu/yolov7
YOLOv7の概要と画期的な点
リアルタイム物体検出は、自動運転、ロボット工学、医療画像解析など、現代のコンピュータビジョンシステムにおいて非常に重要な要素です。これらのタスクでは、多くの場合、モバイルCPUやGPU、あるいは専用のNPUといったエッジデバイス上での高速な推論が求められます。
YOLOv7は、既存のリアルタイム物体検出器が主に「効率的なアーキテクチャの設計」に注力していたのに対し、「推論コストを増やすことなく物体検出の精度を向上させるトレーニングプロセスそのものの最適化」に焦点を当てています。
彼らはこの最適化モジュールと手法を「Trainable bag-of-freebies」と名付けています。これは、トレーニング時にのみ計算コストを要するが、推論時には追加のコストが発生しない、魔法のような「おまけ」のようなもの、とイメージすると分かりやすいでしょう。
効率的なアーキテクチャ「E-ELAN」
YOLOv7は、既存のELAN(Efficient Layer Aggregation Network)をベースに、さらに改良を加えた「Extended-ELAN(E-ELAN)」という新しいアーキテクチャを提案しています。
E-ELANの目的は、ネットワークの学習能力を継続的に強化しつつ、元の勾配伝播パスを破壊しないことです。これを実現するために、グループ畳み込み(Group Convolution)を使って計算ブロックのチャンネルとカーディナリティを拡張し、異なるグループのフューチャーマップをシャッフルしてから結合(merge cardinality)します。
これにより、E-ELANは、より多様な特徴を学習できるようになり、パラメータと計算の利用効率を向上させます。
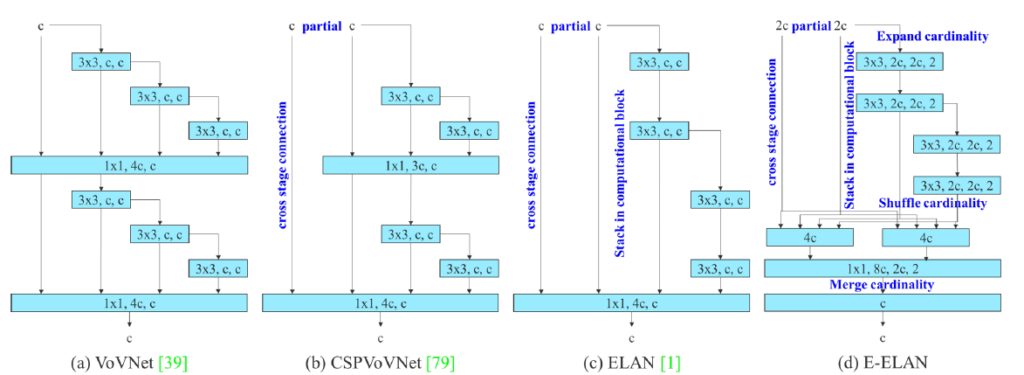
(YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsより引用)
Concatenation-basedモデルのための「モデルスケーリング」
モデルスケーリングは、設計済みのモデルを異なる計算デバイスの要件に合わせて、スケールアップまたはスケールダウンする手法です。既存のモデルスケーリング手法は、主にPlainNetやResNetのようなアーキテクチャを対象としていました。
しかし、DenseNetやVoVNetのような「concatenation-based」モデルにこれらの手法を適用すると、深さ(depth)をスケーリングした際に、一部の層の入力幅が変化してしまう問題がありました。
YOLOv7では、この問題を解決するために、concatenation-basedモデルに特化した新しい複合スケーリング(compound scaling)手法を提案しています。
計算ブロックのdepthファクターをスケーリングする際には、そのブロックの出力チャンネルの変化を考慮し、それに合わせて後続の変換層のwidthファクターもスケーリングします。これにより、モデルの最適な構造を維持したまま、効率的なスケーリングが可能になります。
学習を強化する「Trainable Bag-of-Freebies」
YOLOv7の真骨頂は、推論コストを増やさずに学習時のみ精度を向上させる「Trainable Bag-of-Freebies」という様々なトレーニングの工夫にあります。
Planned Re-parameterized Convolution
RepConv(Re-parameterized Convolution)は、複数の畳み込み層を推論時に一つに結合する技術で、VGGのようなPlainNet系のアーキテクチャでは高い性能を示しました。
しかし、ResNetやDenseNetのような残差接続(residual connection)や結合(concatenation)を持つアーキテクチャにそのまま適用すると、精度が大幅に低下するという問題がありました。
YOLOv7の著者らは、RepConvのidentity connectionが、ResNetの残差やDenseNetの結合が提供する勾配の多様性を損なっていることを発見しました。
そこで彼らは、identity connectionを持たないRepConvNを使用する「Planned Re-parameterized Convolution」を提案します。これにより、RepConvの利点を残しつつ、様々なネットワーク構造に適用できるようになりました。
Coarse-to-fine Lead Guided Label Assigner
ディープネットワークのトレーニングでよく使われる「Deep Supervision」は、ネットワークの中間層に補助的なヘッド(Auxiliary Head)を追加し、補助的な損失(assistant loss)で浅い層の重みをガイドする技術です。これにより、モデルの性能を大幅に向上させることができます。
YOLOv7では、Deep Supervisionとソフトラベル割り当て(soft label assignment)を組み合わせる際に、「補助ヘッドと最終出力ヘッド(Lead Head)にどのようにソフトラベルを割り当てるか」という新たな課題を発見しました。
そこで提案されたのが、「Coarse-to-fine Lead Guided Label Assigner」です。この手法では、学習能力の高いLead Headの予測結果と真値(Ground Truth)をガイドとして使用します。そして、Lead Headにはより詳細な「fine label」を、Auxiliary Headにはより制約を緩めた「coarse label」を割り当てて学習させます。
これにより、Auxiliary Headはより多くの情報を学習しやすくなり、Lead Headはまだ学習できていない残差情報に集中して学習を進めることができます。

(YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsより引用)
驚異的な実験結果
YOLOv7は、様々なベンチマークでその卓越した性能を発揮しています。特にV100 GPU上での性能は目覚ましく、5 FPSから160 FPSの範囲で速度と精度において既存のSOTAモデルを上回ります。
例えば、YOLOv7-E6は、TransformerベースのSwin-L Cascade-Mask R-CNNと比較して、速度で509%高速化し、精度で2% AP向上させています。また、ConvolutionベースのConvNeXt-XL Cascade-Mask R-CNNに対しても、速度で551%高速化し、精度で0.7% AP向上しています。
パラメータ数や計算量に関しても、YOLOv7は多くの既存モデルより優位性を示しています。例えば、YOLOv7-XはYOLOv5-X (r6.1)と比較して、パラメータ数を22%、計算量を8%削減しつつ、APを2.2%向上させています。
これらの結果は、YOLOv7が単に高速であるだけでなく、非常に効率的で高精度な物体検出器であることを明確に示しています。
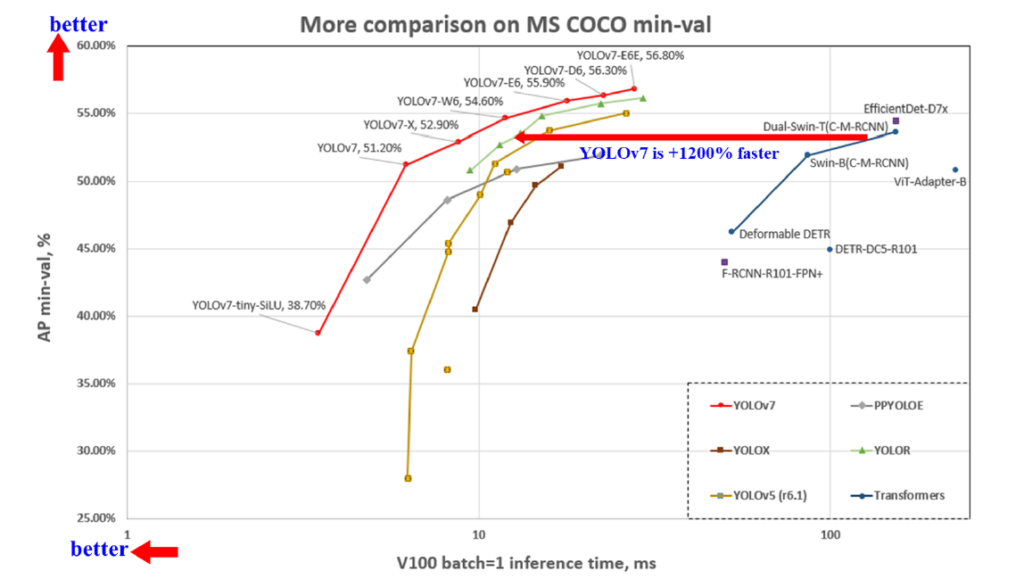
(YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsより引用)
まとめ
YOLOv7は、E-ELANという新しいアーキテクチャ、concatenation-basedモデル向けの複合スケーリング、そして「Trainable bag-of-freebies」と名付けられた様々なトレーニング最適化手法を組み合わせることで、リアルタイム物体検出の分野で画期的な進歩を遂げました。
推論時のコストを増やすことなく学習の効率と精度を向上させるというアプローチは、今後の物体検出器開発における重要な方向性を示すものとなるでしょう。YOLOv7の登場は、より高速で高精度なAIシステムの実装を加速させる可能性を秘めています。