本記事では、大規模言語モデル(LLM)の適応における画期的な手法「LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS」についてご紹介します。この論文は、2021年10月16日にarXivで公開されました(arXiv:2106.09685v2)
導入
近年、GPT-3のような大規模言語モデル(LLM)は、様々な自然言語処理タスクで目覚ましい性能を発揮しています。これらのモデルは、膨大なデータで事前学習された後、特定のタスクに合わせて「ファインチューニング」と呼ばれる追加学習を行うことで、さらに高い精度を実現できます。
しかし、モデルが巨大化するにつれて、ファインチューニングには大きな課題が伴います。例えば、GPT-3 175Bのようなモデルをファインチューニングする場合、タスクごとに1750億もの全パラメータを更新・保存する必要があり、膨大な計算リソースとストレージコストがかかります。
この問題に対処するため、Microsoftの研究者たちは「Low-Rank Adaptation(LoRA)」という新しいアプローチを提案しました。LoRAは、モデルの品質を維持しつつ、学習パラメータ数を劇的に削減し、効率的な適応を可能にします。
大規模言語モデル適応の現状と課題
従来の「ファインチューニング」は、事前学習済みモデルのすべての重みパラメータを更新します。これにより、対象タスクで最高の性能を引き出すことができますが、モデルのサイズが大きくなるとその代償も大きくなります。
具体的には、各タスク専用のモデルインスタンスをデプロイするには、モデル全体のパラメータを保存するためのストレージが莫大になります。また、GPUメモリも大量に消費するため、学習や運用に必要なハードウェアの敷居が非常に高くなってしまいます。
これまでにも、この課題を解決するための様々な「パラメータ効率の良い適応手法」が提案されてきました。例えば「Adapter Layers」は、既存の層の間に小さなアダプタ層を挿入して学習する手法です。しかし、アダプタ層は追加の計算ステップを必要とするため、推論時(特にリアルタイム性が求められるオンライン推論でバッチサイズが小さい場合)にレイテンシが増加するという欠点がありました。
また、「Prefix Tuning」のように、入力プロンプトの一部を学習可能な埋め込みに置き換える手法もあります。しかし、この手法は最適化が難しかったり、入力として使えるシーケンス長が制限されたりする課題がありました。これらの既存手法は、「効率性」と「モデル品質」のどちらか一方を犠牲にする、というトレードオフを抱えていたのです。
LoRAの核心:低ランク適応の仕組み
LoRAの基本的なアイデアは、「事前学習済みモデルを特定のタスクに適応させる際の重み更新は、非常に『低ランク』である」という仮説に基づいています。これは、モデルが学習する新しい情報が、ごく一部の重要な方向に集中していることを意味します。
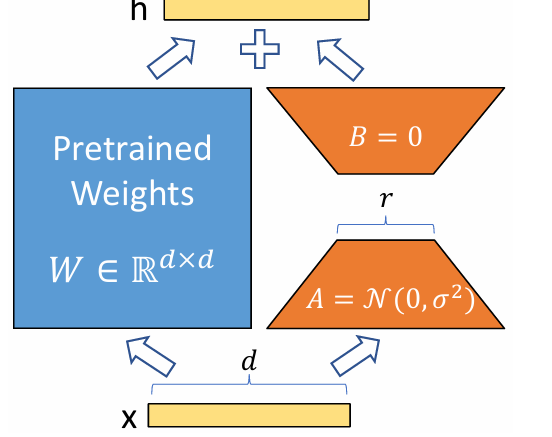
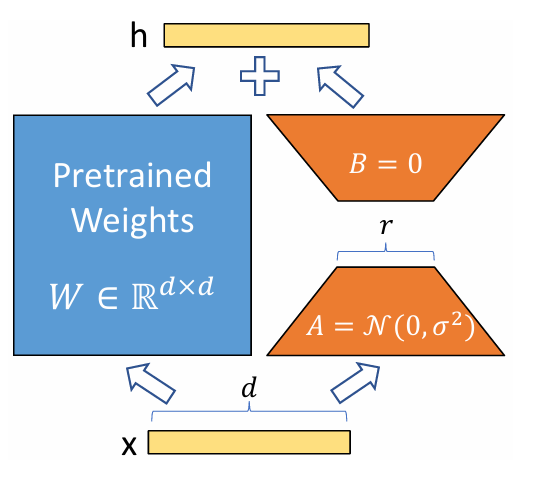
LoRAでは、事前学習済みの重み行列 W0 を固定し、その更新分 ΔW を、小さな2つの行列 B と A の積 BA として表現します。つまり、W0 + ΔW = W0 + BA のようにモデルを再パラメータ化するのです。
ここで、行列 B の次元が d × r、行列 A の次元が r × k となり、r は「ランク」と呼ばれる非常に小さい値(例えば1や2)です。この r が小さいため、B と A のパラメータ数は ΔW 全体のパラメータ数と比較して劇的に少なくなります。
学習開始時には、A はランダムな正規分布で、B はゼロで初期化されます。これにより、ΔW = BA は学習開始時にゼロになり、モデルは事前学習済みの性能からスタートします。学習中には、この B と A のパラメータのみを最適化するため、全パラメータを更新するファインチューニングと比べて、計算コストを大幅に削減できるのです。
LoRAの優れた点
LoRAは、そのシンプルな設計にもかかわらず、大規模言語モデルの運用において数多くの実用的なメリットをもたらします。
まず、最も大きな利点は圧倒的なパラメータ効率です。GPT-3 175Bのような巨大モデルの場合、LoRAは学習対象となるパラメータ数をファインチューニングの約10,000分の1にまで削減できます。これにより、各タスクに特化したモデルを保存する際のストレージ要件が劇的に減少します。
例えば、100個のタスク適応モデルをデプロイしても、ファインチューニングのように100個の巨大モデルを保存する代わりに、1つの事前学習済みモデルと100個の非常に小さなLoRAモジュールを保存するだけで済みます。
次に、GPUメモリ要件の大幅な削減も重要なメリットです。LoRAは、学習中に最適化対象となるパラメータが少ないため、大規模モデルのファインチューニングで消費されるGPUメモリを最大3分の1にまで削減できます。
GPT-3 175Bの例では、必要なVRAMが1.2TBから350GBへと減少しました。これにより、より少ないGPUで学習が可能になり、ハードウェアの導入障壁が大きく下がります。
さらに、LoRAは推論レイテンシを増加させないという決定的な利点があります。デプロイ時には、学習済みの小さな行列 BA を元の重み W0 に明示的に結合し、W = W0 + BA として保存できます。
これにより、モデルは通常のファインチューニング済みモデルと全く同じように機能し、Adapter Layersのような追加の計算ステップが不要になるため、推論速度への影響がありません。
最後に、LoRAはタスク切り替えを非常に容易にします。事前学習済みモデル W0 は共有し、タスクに応じて異なる BA モジュールを差し替えるだけで、迅速にモデルを切り替えられます。これは、多様なタスクに対応するサービスを運用する際に、大きな運用効率の向上につながります。
実験結果:主要モデルでの高い性能
LoRAは、RoBERTa、DeBERTa、GPT-2、そしてGPT-3 175Bといった様々な大規模言語モデルでその性能が検証されています。これらの実験は、GLUEベンチマークのような自然言語理解(NLU)タスクから、E2E NLG ChallengeやWikiSQLのような自然言語生成(NLG)タスクまで、幅広い分野で行われました。
結果として、LoRAは、多くのタスクにおいて全パラメータを更新する「ファインチューニング」と同等か、それ以上のモデル品質を達成できることが示されました。これは、大幅なパラメータ削減とGPUメモリ効率の向上を実現しながらの成果であり、その実用性の高さを示しています。
特に注目すべきは、非常に小さい「ランク r」でも高い性能が得られる点です。例えば、GPT-3 175Bでは、r がわずか1や2といった非常に低い値であっても、十分に競争力のある結果を示しています。これは、大規模モデルの適応に必要な情報が、ごく少数の重要な方向(低ランク)に集約されているというLoRAの根本的な仮説を強く裏付けています。
この研究では、他のパラメータ効率の良い手法との比較も行われ、LoRAがパラメータ効率とモデル品質の両面で優れたバランスを持つことが示されています。
LoRAがなぜ有効なのか?:低ランク更新の洞察
論文では、LoRAがなぜこれほど効果的なのかについて、いくつかの興味深い分析がされています。
まず、Transformerのどの重み行列にLoRAを適用すべきかという問いに対して、特にAttentionモジュールのWq(Query)とWv(Value)の両方にLoRAを適用した際に、最も良い性能が得られることが示唆されています。これは、これらの重みがタスク適応において重要な役割を果たすことを示しています。
次に、最適なランクrは何かという点では、GPT-3のようなモデルでは、驚くほど小さなr(例えば1や2)で十分な性能を発揮することがわかりました。これは、モデルの重み更新ΔWが、タスク固有の情報を表現する上で非常に小さい「intrinsic rank」を持っていることを示唆しています。つまり、複雑な情報が少ない次元に凝縮されているということです。
さらに、ΔWと元の重みW0の関係も分析されています。ΔWはW0のトップ特異方向(最も支配的な特徴)とは強く相関しないことが明らかになりました。むしろ、ΔWはW0の重みの中であまり強調されていなかったものの、特定のダウンストリームタスクにとって非常に重要な特徴方向を「増幅」している可能性が示唆されています。これは、事前学習モデルがすでに多くの特徴を学習しているものの、特定のタスクに適応するためには、それらの中から一部を「選んで強調する」だけで十分だという、興味深い洞察を与えています。
まとめと今後の展望
LoRAは、大規模言語モデルの適応における長年の課題であった「高コスト」と「性能のトレードオフ」を効果的に解決する、非常に強力で実用的な手法です。少ない学習パラメータ、低メモリ消費、そして推論レイテンシの増加なしというメリットは、LLMの幅広い応用を加速させる上で不可欠な要素となるでしょう。