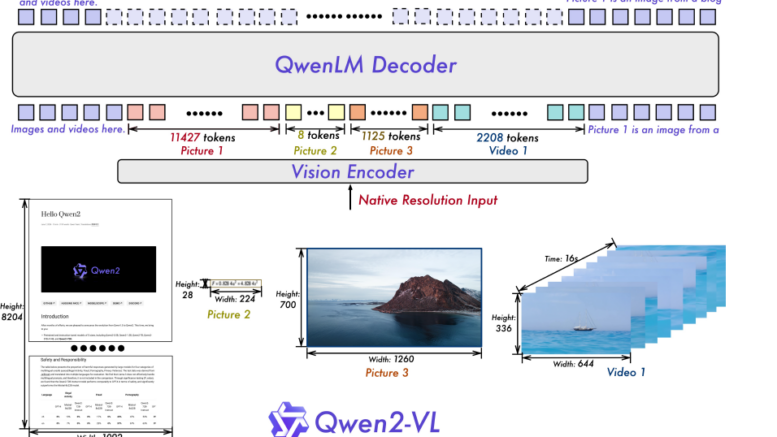
【論文紹介】Qwen2-VL: 任意の解像度で世界を認識する革新的な多モーダルモデル
本日ご紹介するのは、Alibaba GroupのQwen Teamが発…
Read More本日ご紹介するのは、Alibaba GroupのQwen Teamが発…
Read More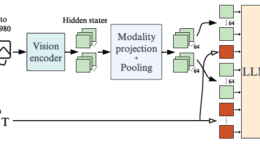
論文タイトル: What matters when building …
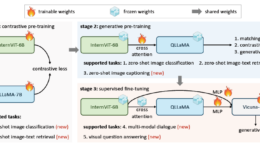
論文タイトル: InternVL: Scaling up Vision…
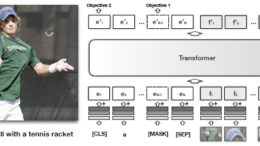
本記事では、2019年にarXivで公開された論文「VISUAL BE…

本記事では、近年注目を集めるVision-Languageモデルの分野…

論文名: CoCa: Contrastive Captioners a…
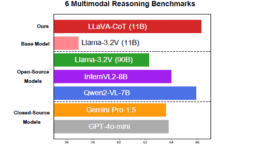
はじめに:VLMの「考える力」を高める 最近、大規模言語モデル(LLM…

今回ご紹介するのは、Vision-Language Pre-train…

大規模なAIモデルが次々と発表される中、DeepMindが発表した「F…

Salesforce Researchが発表した論文「BLIP-2: …