
今までCUDAのインストール方法や、CUDAが必要なGPU版Tensorflowの環境構築などはやってきたのですが、今回は純粋にCUDAを使って並列プログラミングしてみたいと思います。
もともとGPU(ビデオカード)は画面描画などに使われるためのハードウェアであり、故に並列計算の機能が高速です。これは、ディスプレイの各ピクセルを描画することを考える場合、大量の並列計算を高速にこなす必要があるためです。
CPUのコア数が近年8コアなどが多いのに対し、GPUは数千個クラスの並列コア数を持ちます。
故に、そのGPUの機能を画面描画だけではなく、汎用計算に用いて計算を高速化しようという試みは、ここ10年くらいで急速に流行ってきた感はあります。
じゃあ、GPUを使ってどうやって開発するのか? という話ですが、NVIDIA製のGPUを使っている場合には、CUDAを使うのが楽です。
CUDAはNVIDIAが開発しているGPU向けの汎用並列プログラミングモデルであり、C++を拡張したものなので、C++のプログラミングに慣れている人なら割とすんなりと動かすことができると思います。
一方、最近の誤解としてGPUを使えば何でも速くなるのか? というのがありますが、どんなプログラムでも速くなるわけではありません。
一般的に、
(1) GPUを使う場合、GPUのメモリにデータを転送する必要があるため、データ転送のオーバーヘッドが発生する
(2) GPUは単純並列計算向けのため、if文などが大量に入るソースコードでは十分な並列化性能を発揮できない
あたりの理由から、データ転送が多いコードや、if文が多いコードに適用しても、それほど並列化性能は望めないと考えられます。
少し前置きが長くなりましたが、早速CUDAのプログラムを作ってみましょう。
今回はCUDAがインストール済の状態からスタートしますので、CUDAのインストールは以下の記事を参考にしてください。
関連記事:CUDA 8.0の導入と環境構築(Windows 10)
上記記事はCUDA8.0の環境構築ですが、今回はCUDA9.0を使いました。基本的にはCUDA8でもCUDA9でも同じように動くとは思います。
今回の環境
・OS : Windows10(64bit)
・GPU: GeForce GTX 1060
・Visual Studio 2015 インストール済
・CUDA 9.0 インストール済
プログラミング方法
いくつかやり方があると思いますが、今回はコンソールアプリケーションを作成し、その中でCUDAのプログラムを動かしていきたいと思います。
(1) Visual Studioを起動し、プロジェクトを作成
新しいプロジェクトを作成する画面を起動し、Visual C++のタブから「Win32 コンソールアプリケーション」を選択していきます。
プロジェクト名は任意ですが、ここでは「CUDATestApp1」としました。
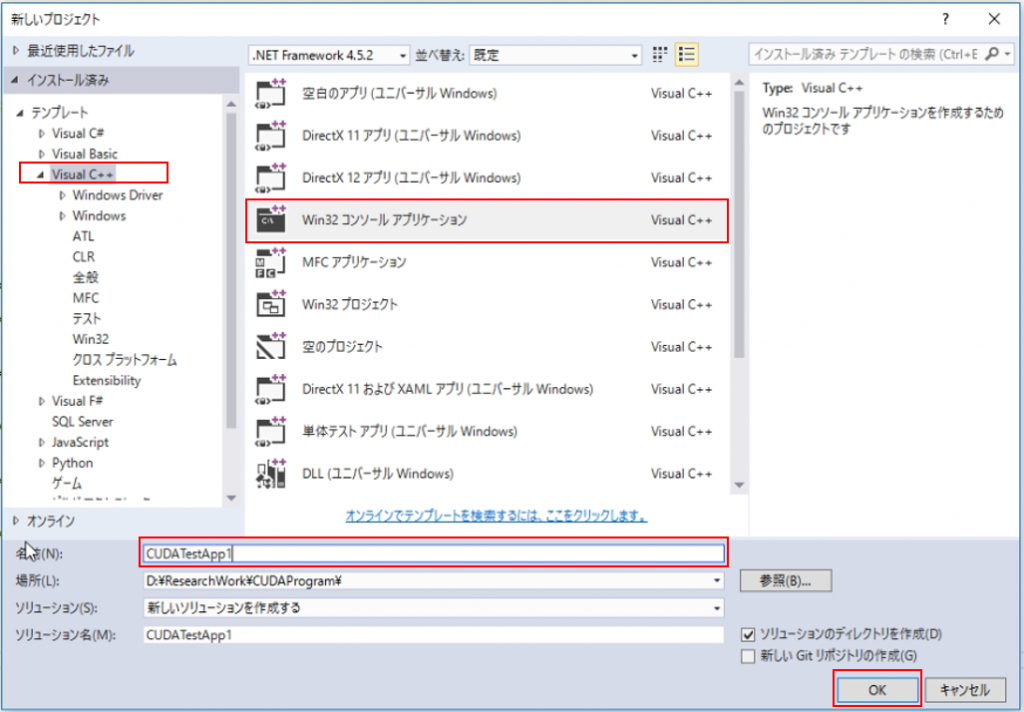
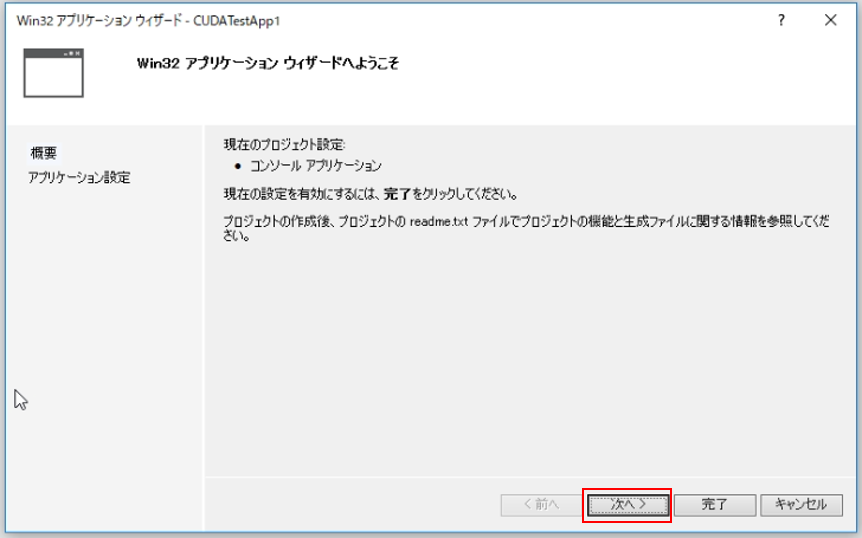
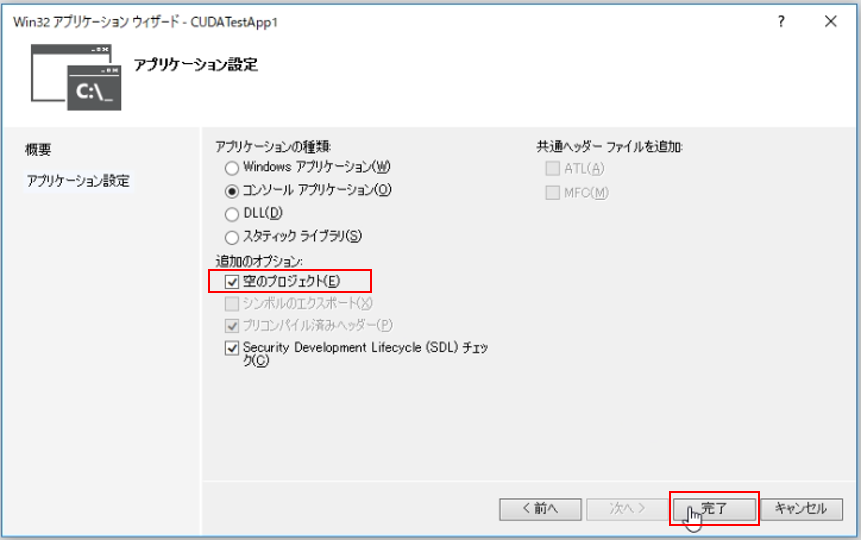
アプリケーションウィザードで「空のプロジェクト」にチェックを入れ、完了します。これにてプロジェクトの作成は完了です。
(2) CUDAのコードを追加
プロジェクトができたので、CUDAのコードを追加してみます。
ソリューションエクスプローラーからソースファイルフォルダを右クリックし、追加⇒新しい項目で、新しいファイルを追加します。
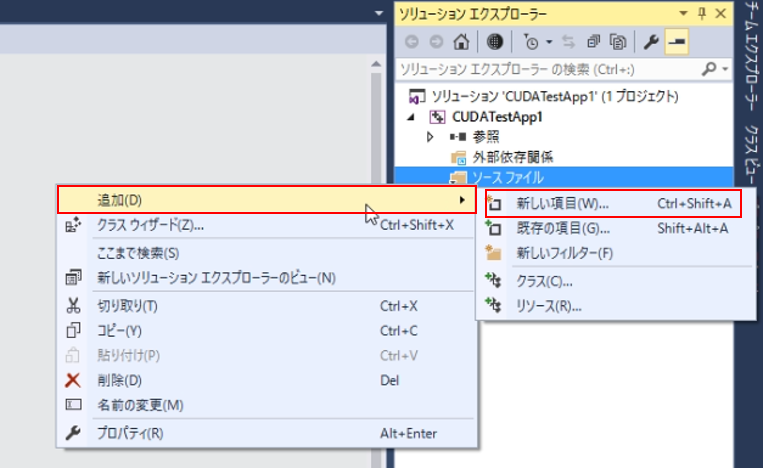
今回は「.cu」形式のファイルを追加します。これはCUDAのコードを記述できるファイルです。
左タブの「NVIDIA CUDA 9.0」を選択し、「CUDA C/C++ File」を選択し、適当な名前を付けて追加します。
※ ここで左タブにCUDAがない場合には、CUDAのインストールが正常に行われていない可能性があるため、CUDAのインストールをやり直すなど、見直した方がいいかもしれません。
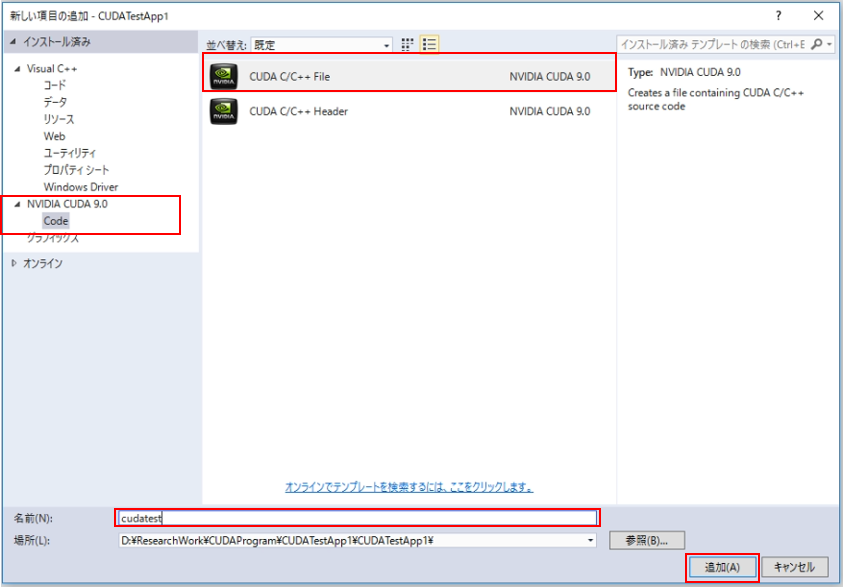
これで、「.cu」のファイルが追加されたと思います。
デフォルトでは何も書かれていないため、中身は空っぽです。
(3) ビルドのために必要な設定
さて、それではビルドのために必要な設定をいくつか見ていきましょう。
(a) ビルドカスタマイズファイルの選択
まず初めに、ソリューションエクスプローラーからプロジェクト名を右クリックし、「ビルドの依存関係」⇒「ビルドのカスタマイズ」をクリックしてください。
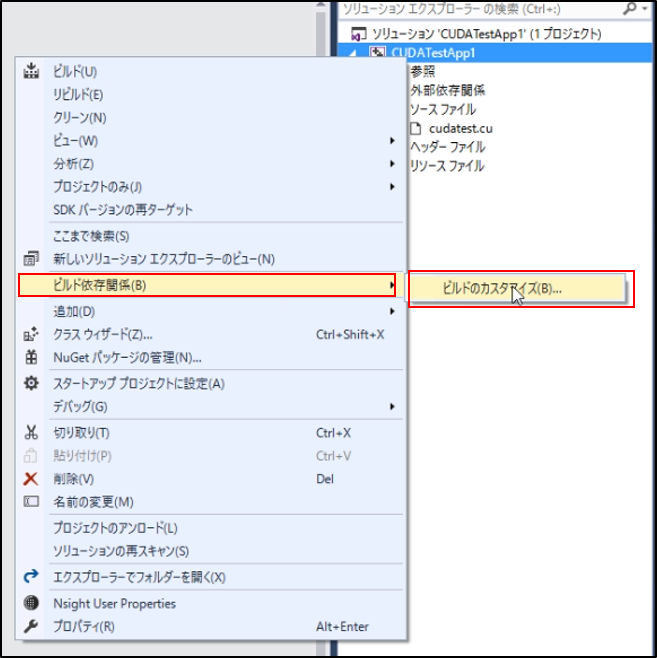
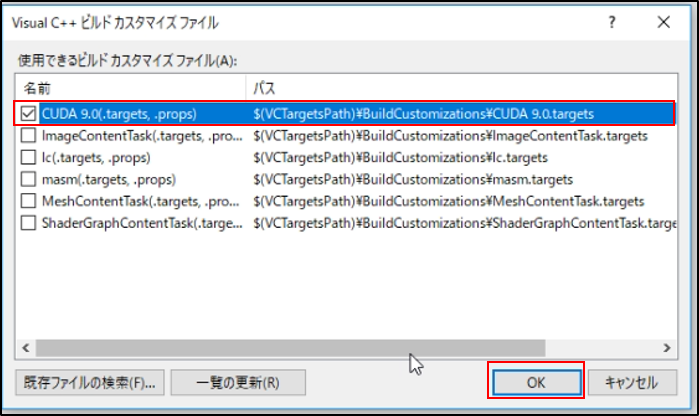
すると、以下のようにカスタマイズファイルが選択できます。
デフォルトではCUDA9.0が選ばれていなかったので、CUDA9.0にチェックしてOKを押します。
(b) ビルド構成をRelease/x64にしておく
今回はRelease/x64でビルドすることを前提に進めます。

(c) ソースコードがビルドに「含めない」になっていないか確認する
(2)のところで追加した「.cu」形式のソースコードがビルドされる対象になっていないケースがあります。
ちょっと下の画像が見づらいですが、追加した「.cu」形式のコード(私はcudatest.cuとしました)の上で右クリックし、プロパティを開きます。
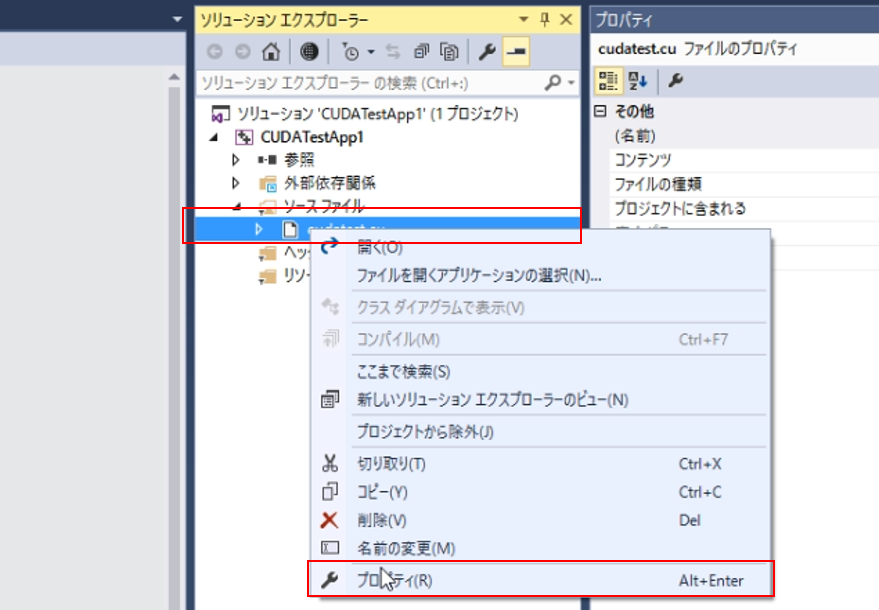
ここで「ビルドに含めない」に設定されている場合、コードがビルドされません。
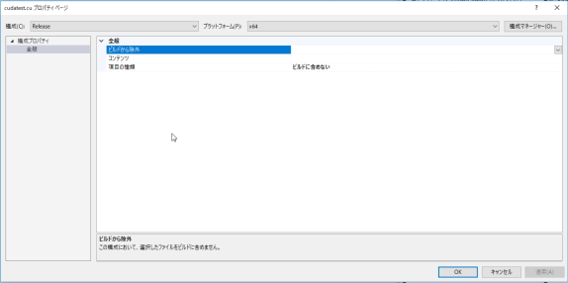
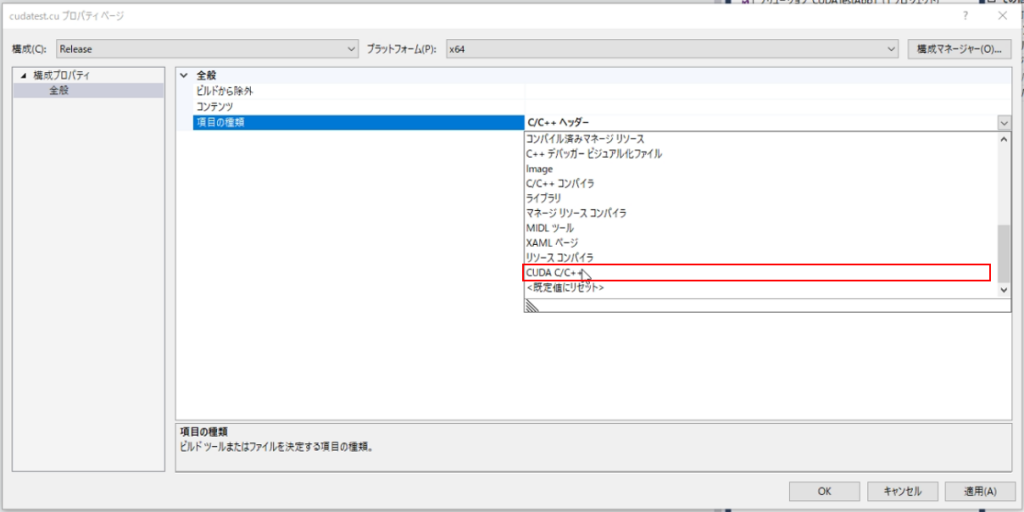
項目の種類を「CUDA C/C++」に変更し、ビルドから除外を「いいえ」に設定します。
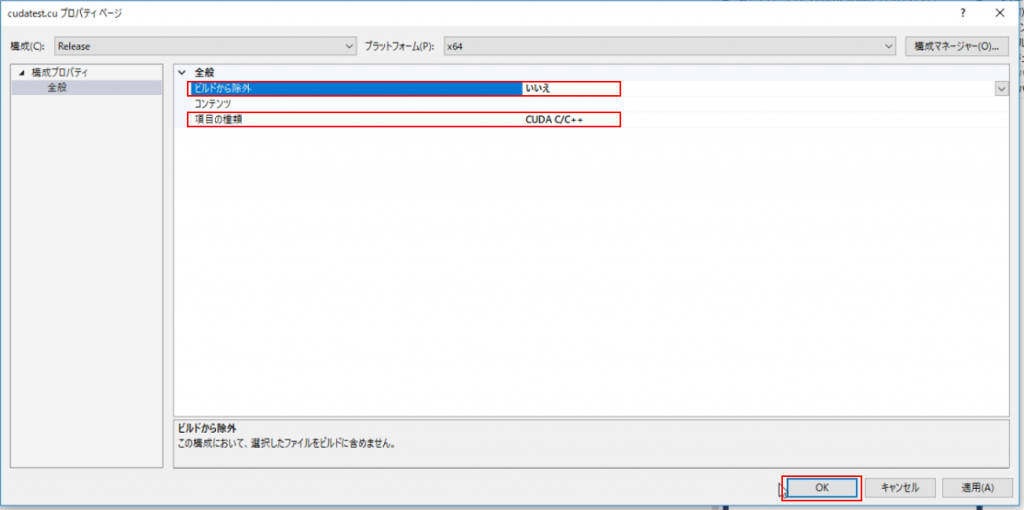
これで、cudatest.cuがビルドの対象となりました。
(d) CUDAのライブラリをリンクする
最後にCUDAのライブラリへのリンクを行います。
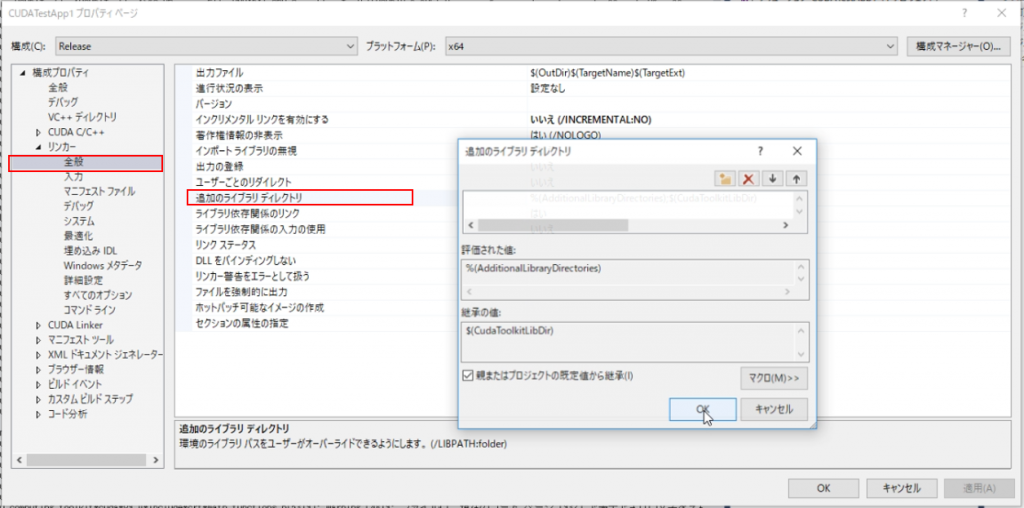
プロジェクト名を右クリック⇒「プロパティ」からプロジェクトのプロパティページを開きます。
左タブ「リンカー」⇒「全般」より、「追加のライブラリディレクトリ」を選択し、ライブラリディレクトリへのパスを追加します。
CUDAをデフォルトでインストールした場合、私は「C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64」がライブラリのパスでした。
「NVIDIA GPU Computing Toolkit」というフォルダの中にあるlibフォルダ(x64)を指定すればよいです。
次に追加の依存ファイルを追加します。
ここでは「cudart_static.lib」を追加しました。
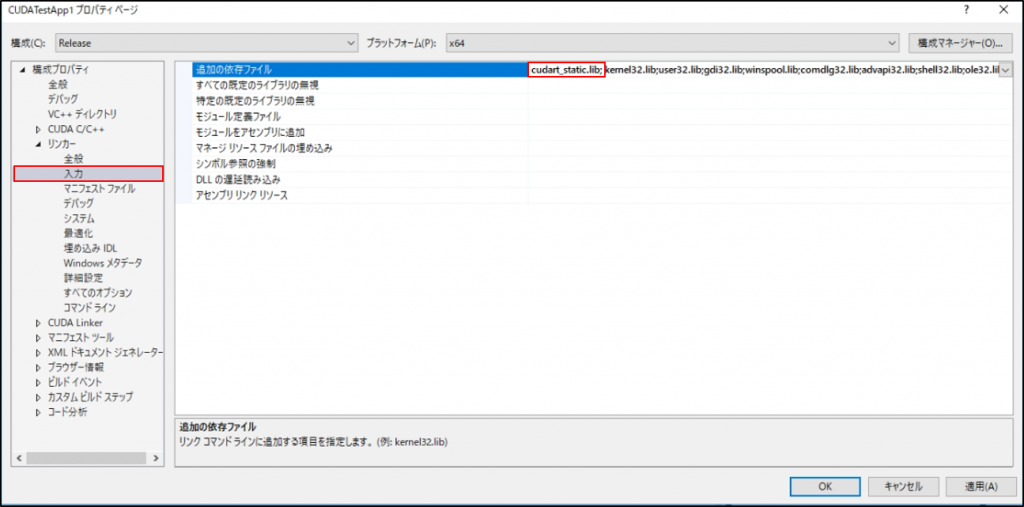
これでライブラリへのリンクは完了です。
(4) テストコードを実行する
以下にCPUとGPUで同じ計算を行うテストコードを置きました。
設定が正しく行われていれば、本コードのビルドを行うことができるはずです。
細かいコードの説明は割愛しますが、乱数で設定した位相を元に “SINΘ×SINΘ+COSΘ×COSΘ” を計算するプログラムです。
25行目でNの数を設定でき、N=100なら100個の乱数に対し、”SINΘ×SINΘ+COSΘ×COSΘ”が計算され、最後に確認のために総和が計算されます。
“SINΘ×SINΘ+COSΘ×COSΘ”はΘの値によらず1なので、N=100なら最終結果は1が100個で100になります。
比較用にCPU用関数(C++ベース)とGPU関数(CUDA利用)を用意しており、6~10行目がGPUを使用した場合、13~18行目がCPUを利用した場合です。
23行目の「bool GPU = true;」の部分を「bool GPU = false;」とすればCPU版関数で動作するので、計算時間の比較を行うことが可能です。
(5) 一応実行結果
N=1,000,000のとき、CPU動作:16[ms] / GPU動作:206[ms]
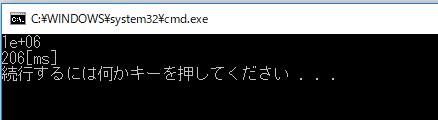
N=10,000,000のとき、CPU動作:149[ms] / GPU動作:235[ms]
と、CUDAを使った場合の方が遅いという結果になりました。
ただ、Nを増やしたときにCPUの場合は動作時間が素直に10倍近くになっているのに対して、GPU動作の場合は過度に増えておらず、並列計算の高速化自体は上手く働いていそうな雰囲気です。
今回のプログラムは”SINΘ×SINΘ+COSΘ×COSΘ”を計算するだけのプログラムであるが故に、GPU側に領域を確保したり、データコピーをしたりする部分の処理時間のオーバーヘッドが大きく、そのあたりのオーバーヘッドがないCPU動作の方が早くなっているような気がします。あとはGPUそのものの性能があまり高くないからかもしれません。
まとめ
狙った通りの高速化性能の確認……! とまではいきませんでしたが、CUDAのコードをビルドし、動作することを確認できました。
今回はテストコードの内容についてもあまり説明できなかったため、今後はそのあたりも紹介しつつ、CUDAを使うことで高速化が見込めそうなプログラムには、どんどんCUDAを適用していけるように勉強していきたいです。
Be the first to comment on "CUDAでGPUプログラミング VisualStudioでのビルド方法"