
マルチモーダルLLM(Large language Models)は、ChatGPTなどに代表されるLLMに画像などのテキスト以外も入力できるようにしたLLMのことです。
最近は、テキストだけではなく音声や画像、動画などさまざまなものを入力できるマルチモーダルLLMの注目度が高まってきています。
LLaVA(Large Language and Vision Assistant)はMicrosoft ResearchとUniversity of Wisconsin-Madison、Columbia Universityによって開発されたマルチモーダルLLMで、テキストの他に画像の入力が可能です。
本日は「LLaVA」を、ソースコードをダウンロードしてきて動かしてみたいと思います。
※ 2024/06/24時点の情報です
今回の記事でできること
学習済(Pretrain)モデルをダウンロードし、コンソール上で画像を指定し、マルチモーダルLLMとChatを行うところまで実現します。モデルの訓練については、今回の記事では扱いません。
今回の実行環境
Ubuntu 24.04 (WSL2 / Windows11上)
WSLはWindowsの上でUbuntuを動かすことのできる仕組みです。使ったことのない方は、以下の記事などを参考に環境構築してみてください。今回はWSL上のUbuntu環境でLLaVAを動かします。
実行手順
前提
実行前に、Anacondaを導入する必要があります。既にまとめられているサイトが多くあるので「Anaconda Ubuntu 環境構築」等で調べてみてください。
手順1:実行環境の構築
基本は公式のGithubに記載されている通りの手順で環境構築が可能ですが、実際に発生したエラーなども交えて説明を行います。
Ubuntu上で以下の順にコマンドを実行します。まずはGitからリポジトリをクローンし当該フォルダに入ります。
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVALLaVA用の仮想環境「llava」を構築し、仮想環境「llava」を有効にした上でpipをアップグレードします。
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip 最後に以下のコマンドで必要なライブラリ等のインストールが完了します。
pip install -e .手順2:CLIでLLaVAを実行
今回はコマンドライン上でそのままLLaVAを実行してみます。公式に紹介されている実行コードは以下で、モデル(liuhaotian/llava-v1.5-7b)や、マルチモーダルLLMに入力する画像(https://llava-vl.github.io/static/images/view.jpg)はインターネット経由で取得できます。任意の画像を入力したい場合には、画像のパスを変更すればよさそうです。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-4bit上記を実行したところ、まずは以下のエラーが出ました。
The new behaviour of LlamaTokenizer (with self.legacy = False) requires the protobuf library but it was not found in your environment.
protobuf libraryが必要と言われているので、以下のコマンドで入れてみます。
pip install protobufProtobufを入れて再度実行してみます。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-4bitすると、Userという文字が出てきて、テキスト入力を促されます。

とりあえず適当にチャットを入力してみました。
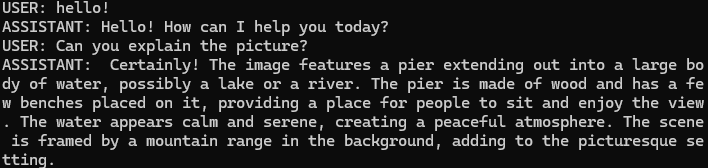
ASSISTANTと会話が行えていることがわかります。画像はhttps://llava-vl.github.io/static/images/view.jpgにアクセスしてみるとわかりますが、概ね説明も正しそうに見えます。
まとめ
今回はマルチモーダルLLMであるLLaVAを動かしてみました。GoogleのGeminiやGPT-4Vと比較すると知名度は劣るのかもしれませんが、比較的簡単に動作させることができます。