
Sentence transformerはHugging Faceが提供する自然言語処理のライブラリであり、文や文章の意味をベクトル表現に変換する深層学習手法です。
例えば「This is a pen.」のようなある特定の文章を、例えば384個の要素から成るベクトルとして表現することができます。そして、同じような意味を持つ文章ほど、同じようなベクトルに変換されます。そのため、このベクトル表現は、文間の類似度計算や文章分類、情報検索など、様々なタスクに利用できます。
Transformerというと難しそうに感じてしまいますが、今はPythonで簡単にSentence Transformerのプログラムを実装することができます。
また、たくさんの学習済モデルが公開されているため、自分のタスクに適したモデルを探すことで、学習等をせずに活用することもできます。
今回は、Sentence transformerを用いて二つの文章の類似度を測定します。
Sentence transformerの環境構築
Sentence Transformerの環境構築は、非常に簡単です。基本的には、Pythonと必要なライブラリをインストールするだけです。以下のようにpipを利用してSentence transformerをインストールします。
pip install -U sentence-transformersSentence transformerで文章の類似度を測定するソースコード
以下にSentence transformerで二つの文章(”This is a cat.”と”This is a dog.”)の類似度を計算するプログラムを示します。
from sentence_transformers import SentenceTransformer, util
MODEL_NAME = 'paraphrase-MiniLM-L12-v2'
def calcCosSim(sentence1: str, sentence2: str, model) -> float:
embeddings1 = model.encode(sentence1, convert_to_tensor=True)
embeddings2 = model.encode(sentence2, convert_to_tensor=True)
similarity_tensor = util.pytorch_cos_sim(embeddings1, embeddings2)[0][0]
similarity = similarity_tensor.to('cpu').detach().numpy().copy()
return similarity
def main():
model = SentenceTransformer(MODEL_NAME)
sentence1 = "This is a cat."
sentence2 = "This is a dog."
similarity = calcCosSim(sentence1, sentence2, model)
print("similarity = ",similarity)
if __name__ == "__main__":
main()このコードは、2つの文の意味的な類似度を計算するプログラムです。自然言語処理において、意味が近い文同士は高い類似度を示します。
コードの主要な部分
- 必要なライブラリのインポート
- SentenceTransformer:文をベクトル(数値のリスト)に変換し、類似度計算を行うためのライブラリ
- モデルの定義
- MODEL_NAME: 使用する事前学習済みモデルの名前を指定。このモデルは、文を意味を表すベクトルに変換するように訓練されています。
- 類似度計算関数calcCosSim
- 2つの文(sentence1、sentence2)を受け取り、それらをモデルを使ってベクトルに変換します。
- util.pytorch_cos_sim関数を使って、2つのベクトルのコサイン類似度を計算します。コサイン類似度は、-1(全く異なる意味)から1(非常に近い意味)までの値を取ります。
- 計算結果をcpuに転送し、NumPy配列に変換して返します。
- メイン関数main
- SentenceTransformerを使ってモデルをロードします。
- 2つの文を定義します。
- calcCosSim関数を使って類似度を計算し、結果を表示します。
コードの実行結果
このコードを実行すると、”This is a cat.” と “This is a dog.” の類似度が計算され、出力されます。これらの文は、「This is a」という部分までは同じですが、「cat」と「dog」は異なる意味を持つため、類似度は1よりも小さくなります。
私の環境では以下の類似度が出力されました。
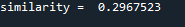
ポイント
- 事前学習済みモデルを使用することで、文の意味を捉えたベクトル表現を得ることができます。
- コサイン類似度は、ベクトル間の角度に基づいて計算されるため、ベクトルの長さではなく方向が重要になります。
- このコードは、文章間の類似度を計算するだけでなく、文章分類、情報検索、質問応答システムなど、様々な自然言語処理タスクに応用できます。
注意点
- detach().numpy().copy()の部分は、PyTorchのテンソルをNumPy配列に変換するために必要です。これにより、計算結果をPythonの他の部分で簡単に利用できるようになります。
他の学習済モデルを利用する
今回のプログラムでは学習済モデルとして
MODEL_NAME = 'paraphrase-MiniLM-L12-v2'を指定していますが、さまざまなモデルが提供されているので、いろいろ試して自分の試したいタスクに合うモデルを選択するとよいでしょう。モデルによって使える言語なども決まっているため、特定の言語の文章の類似度を測定するためには、適したモデルを利用する必要があります。
例えば、以下で多数のモデルが公開されています。
上記のサイトで、例えば今一番Trendingになっている「BAAI/bge-3」を試してみましょう。
モデルによりますが、多くのモデルはモデルの名前を指定するだけで、モデルをダウンロードしてきて動作します。
MODEL_NAME = 'BAAI/bge-m3'上記のモデルで実行した場合の結果は以下となり、得られるベクトル表現が変わるので、結果として類似度が変化したことがわかります。
