OpenAIから発表された論文「Learning Transferable Visual Models From Natural Language Supervision」は、コンピュータビジョン分野に新たな風を吹き込む画期的な研究です。
arXivリンク: https://arxiv.org/abs/2103.00020
この論文は、自然言語の力を借りて、これまでの固定されたカテゴリ認識にとらわれない、非常に汎用性の高い画像認識モデル「CLIP(Contrastive Language-Image Pre-training)」を提案しています。
従来の画像認識システムの課題
これまで、最先端のコンピュータビジョンシステムは、あらかじめ定義された固定のオブジェクトカテゴリを予測するように学習されてきました。例えば、「犬」「猫」「車」といった特定のラベルを持つ大量の画像を使って学習させるのが一般的です。
しかし、この方法には限界がありました。もし新しい視覚的な概念をモデルに認識させたい場合、そのための追加のラベル付きデータを大量に用意し、モデルを再学習させる必要があったのです。これは、時間もコストもかかる大きな課題でした。
CLIPとは? 自然言語による新しいアプローチ
CLIPは、この課題を解決するために、画像とそれに対応するテキストのペアから直接学習するというアプローチを採用しています。インターネット上には、画像とそれを説明するテキスト(キャプションなど)が膨大に存在します。CLIPは、この「自然言語による教師情報」を最大限に活用します。
具体的には、CLIPは「どのキャプションがどの画像と一致するか」を予測するというシンプルな事前学習タスクを行います。4億組もの(画像, テキスト)ペアを使って学習することで、画像とテキストの関係性を深く理解するモデルが構築されます。
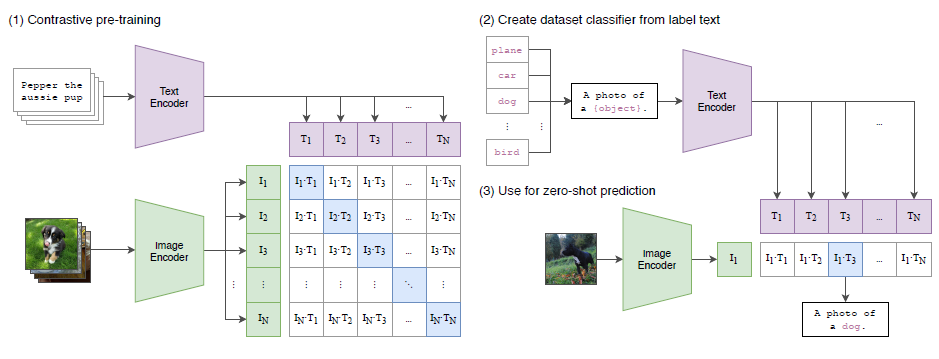
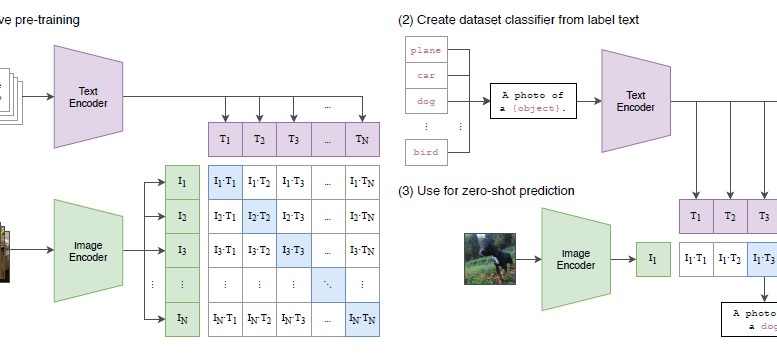
この図は、CLIPの全体的なアプローチを示しています。まず、Image EncoderとText Encoderが、画像とテキストをそれぞれ特徴量に変換します。事前学習段階では、正しい画像とテキストのペアの類似度を最大化し、間違ったペアの類似度を最小化するように学習します。
学習後、新しいタスクに適用する際には、そのタスクのカテゴリ名をText Encoderに通すことで、自動的に分類器の「重み」を生成します。これにより、学習時に見たことのないカテゴリに対しても、追加の学習なしで分類できる「Zero-shot転送」が可能になるのです。
Zero-shot転送の驚くべき能力
CLIPの最大の魅力は、Zero-shot転送能力にあります。これは、事前に特定のタスクのデータで学習していなくても、自然言語でタスクを指示するだけで、そのタスクを実行できる能力のことです。
例えば、モデルに「これは何の写真ですか?」と問いかけ、候補として「犬の種類の写真」「猫の種類の写真」といったテキストを与えれば、モデルは最も一致する画像を推測します。
論文では、「ResNet-50」という有名な画像認識モデルが128万枚のImageNetデータで学習して達成した精度と、CLIPがImageNetの学習データを使わずにZero-shotで達成した精度が同等であったと報告されています。これは非常に驚くべき結果です。
また、Zero-shot性能をさらに向上させるために、「Prompt Engineering」と呼ばれる手法が有効であることが示されています。これは、例えば単に「dog」というラベルを与えるのではなく、「A photo of a {label}」のように、より自然な文脈を与えることで、モデルの理解を助けるアプローチです。
CLIPが様々なタスクで発揮する力と堅牢性
CLIPは、OCR(光学文字認識)、動画内の行動認識、地理位置特定、きめ細かいオブジェクト分類など、30種類以上の多様なコンピュータビジョンデータセットでベンチマークされています。
多くのタスクで、追加のデータによる学習なしで、既存のタスク特化型モデルに匹敵する、あるいは上回る性能を発揮しています。これは、CLIPが単に画像の特徴を抽出するだけでなく、様々な視覚的概念を「理解」していることを示唆しています。
特に注目すべきは、CLIPモデルの「堅牢性」です。従来の画像認識モデルは、学習データとは少し異なる分布の画像(例えば、異なる撮影環境、スタイル、歪みなど)に対して性能が大きく低下する傾向がありました。
しかし、CLIPのZero-shotモデルは、ImageNetV2やObjectNetのような、意図的に分布シフトさせたデータセットに対しても、既存のモデルと比較して非常に高い堅牢性を示すことが明らかになっています。
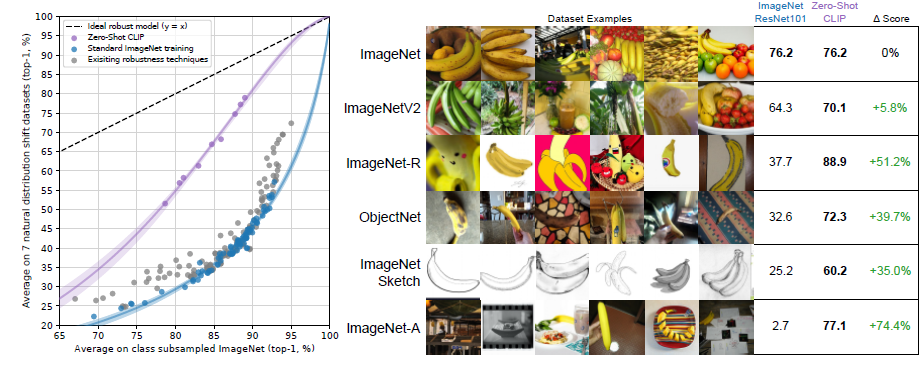
(Learning Transferable Visual Models From Natural Language Supervision より引用)
この図は、CLIPのZero-shotモデルが、標準的なImageNetモデルと比較して、分布シフトに対してはるかに堅牢であることを示しています。左側のグラフは、Zero-shot CLIPが「堅牢性ギャップ」を最大75%縮小することを示し、右側のバナナの画像は、ImageNetと異なる様々な環境で撮影されたバナナに対して、CLIPがどのように予測するかを具体的に示しています。
CLIPは、幅広い視覚的概念を学習することで、現実世界の多様な画像に対しても、より安定した性能を発揮できる可能性を秘めています。
倫理的側面と限界
論文では、CLIPの倫理的側面についても深く議論されています。モデルがインターネット上のデータから学習するため、社会的なバイアス(人種、性別などに関するステレオタイプ)も学習してしまう可能性があります。例
えば、FairFaceデータセットを使った実験では、一部のデモグラフィックグループに対して誤分類率が高くなるケースや、特定の職業が特定の性別に偏って関連付けられるバイアスが確認されています。
また、CLIPは非常にデータ効率が良いわけではなく、数百億もの画像を使って学習する必要があるという限界も指摘されています。真に柔軟なAIには、より少ないデータで学習できる能力も求められます。
まとめと今後の展望
CLIPは、自然言語からの教師あり学習というアプローチで、コンピュータビジョンモデルの汎用性とZero-shot転送能力を大幅に向上させました。これにより、これまで想像もしなかったような多様なアプリケーションが、追加の学習データなしで実現できるようになるかもしれません。
一方で、モデルのバイアスや、より高度な推論を必要とするタスクへの対応など、解決すべき課題も残されています。しかし、この研究は、AIが人間のように「指示」を理解し、未知のタスクに適応する未来への大きな一歩となるでしょう。