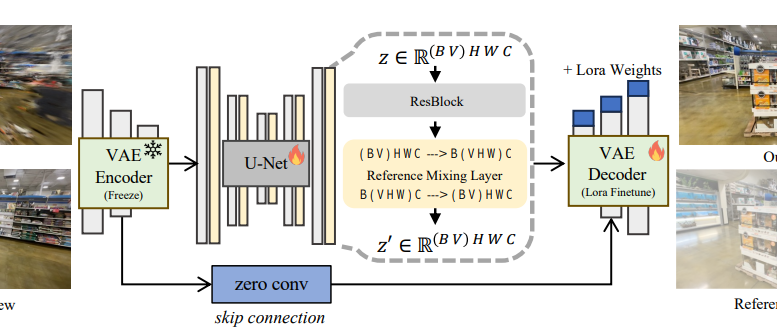
本記事では、NVIDIAの研究チームが発表した論文「DIFIX 3D+: Improving 3D Reconstructions with Single-Step Diffusion Models」についてご紹介します。
この論文は2025年3月3日にarXivで公開され、コンピュータビジョンのトップカンファレンスCVPR2025で発表されました。
arXiv:2503.01774v1
はじめに:3D再構成の進化と残された課題
近年、Neural Radiance Fields (NeRF) や3D Gaussian Splatting (3DGS) といった技術の登場により、現実世界を3Dで再現し、様々な視点から新しい画像を生成する「新規視点合成」の分野は目覚ましい進歩を遂げています。しかし、これらの強力な手法にも、まだ課題が残されています。
特に、学習に使われたカメラの位置から遠い視点や、情報が少ない領域(制約が不十分な領域)から画像を生成しようとすると、ノイズや歪み、欠損といった「アーティファクト」が発生し、リアリティが損なわれることが問題でした。この論文「DIFIX 3D+」は、この課題に対し、ディフュージョンモデルという最新の画像生成技術を用いて、効率的かつ高品質に解決する新しいパイプラインを提案しています。
DIFIX 3D+の核となるアイデア:拡散モデルで3Dを「修正」する
DIFIX 3D+の中心にあるのは、「DIFIX」と呼ばれるシングルステップの画像ディフュージョンモデルです。ディフュージョンモデルは、インターネット上の膨大な画像データから学習することで、現実世界の画像のパターンを深く理解しています。
DIFIXは、この強力な生成能力を活かして、3D再構成によって生成されたノイズのある画像を「修正」することに特化して訓練されます。
DIFIX 3D+は、このDIFIXモデルを大きく2つの段階で活用します。
- 3D表現の質を向上させる「プログレッシブ3D更新」:
学習中に、3Dモデルから仮の新規視点画像を生成し、それをDIFIXで修正します。この修正された「きれいな」画像を再び3Dモデルの学習データとしてフィードバックすることで、3Dモデル自体の品質、特に情報が不足している領域の精度を段階的に向上させます。 - リアルタイムで最終画像を補正する「ポストレンダリング処理」:
3Dモデルによる画像生成後、最終的な出力画像に対してもDIFIXを適用します。これにより、微細なノイズや不自然さをさらに取り除き、よりフォトリアルな画像を生成します。DIFIXは「シングルステップ」で動作するため、このポストレンダリング処理は非常に高速で、ほぼリアルタイムでの適用が可能です。

上の画像はDIFIX 3D+を適用して修正された新規視点画像と、その他の手法の比較です。
元のNeRFの画像と比較して、ディテールが鮮明になり、全体的にノイズが大幅に軽減され、より高品質で自然な画像になっていることが分かります。
DIFIXモデルの訓練:アーティファクトを意図的に作り出す
DIFIXモデルは、あえて「汚い画像」と「きれいな画像」のペアを大量に用意して学習します。これにより、DIFIXはどんなアーティファクトがどのように発生し、それをどのように修正すれば良いかを学びます。
この「汚い画像」は、実際には次のような様々な戦略で意図的に生成されます。
- サイクル再構成: 一度3Dモデルでシーンを再構成し、その3Dモデルを使って別の視点から画像をレンダリング。その画像を再度3Dモデルの学習に使って、さらにノイズのある画像を生成します。
- モデルの不十分な学習 (Model Underfitting): 通常の学習時間よりも短く設定し、意図的に3Dモデルの学習を不完全にすることで、アーティファクトのある画像を生成します。
- クロスリファレンス: 複数カメラで撮影されたデータセットの場合、1つのカメラのデータだけで3Dモデルを学習し、他のカメラからの視点を「新規視点」として汚い画像を生成します。
このようにして作られた、様々な種類のアーティファクトを含む「汚い画像」と、それに対応する「きれいな画像」のペアを用いて、DIFIXは効率的に修正能力を学習します。
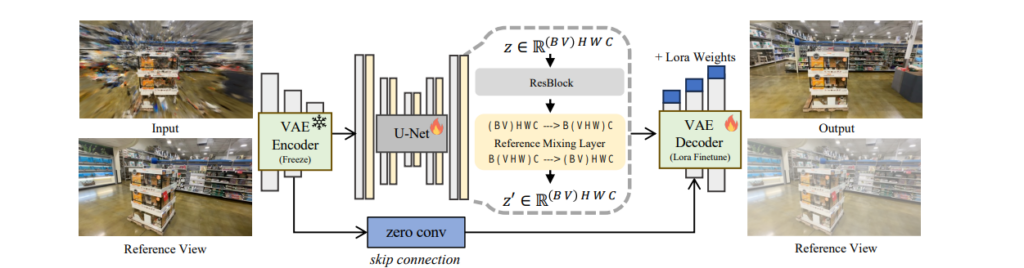
上の画像のInputは、DIFIXの学習に使われる「汚い画像」の一例です。このように、元の3D再構成で発生しがちなノイズや歪みが意図的に作り出され、これを修正するようにDIFIXが学習します。
実験結果:大幅な品質向上と高い汎用性
DIFIX 3D+は、様々なデータセット(一般的なシーンや自動運転シーンなど)で評価され、既存の多くの手法を上回る優れた性能を示しました。
特に、画像生成のリアルさを測る指標であるFIDスコアでは、ベースライン手法と比較して平均2倍もの改善を達成しています。また、画質の細かさを測るPSNRも1dB以上の向上を見せており、単にリアルなだけでなく、元のシーンに忠実な画像を生成できることが示されました。
さらに、DIFIX 3D+はNeRFと3DGSという異なる3D再構成バックボーンの両方で利用できる汎用性も持っており、非常に実用的なソリューションと言えます。
まとめ
DIFIX 3D+は、シングルステップのディフュージョンモデル「DIFIX」を活用することで、3D再構成におけるアーティファクトの問題を効果的に解決する画期的な手法です。
その最大の貢献は、
- プログレッシブな3D更新によって、3D表現自体の品質と一貫性を高めること。
- リアルタイムポスト処理により、最終的なレンダリング画像をさらに高精細化できること。
この技術により、より高品質でフォトリアルな新規視点合成が、これまで以上に効率的に実現できるようになるでしょう。
参考情報
- 論文タイトル: DIFIX 3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
- 著者: Jay Zhangjie Wu 他
- arXiv公開日: 2025年3月3日
- プロジェクトページ: https://research.nvidia.com/labs/toronto-ai/difix3d