論文タイトル: What matters when building vision-language models?
arXiv: arXiv:2405.02246v1
はじめに:Vision-Language Model (VLM) の重要性
近年、画像とテキストの両方を理解し、テキストとして応答する「Vision-Language Model (VLM)」が大きな注目を集めています。
PDFからの情報抽出、グラフや図の説明、画像内のテキスト認識、さらにはウェブページのスクリーンショットからコードを生成するといった多様なタスクで活躍が期待されています。
しかし、これまでのVLM研究では、モデルの設計に関する重要な決定(どのようなバックボーンを使うか、どう学習させるかなど)が、必ずしも明確な根拠に基づいて行われていないという課題がありました。
これにより、どの設計選択が実際にモデル性能を向上させているのかが分かりにくく、分野全体の進歩を妨げる要因にもなっていました。
本論文の目的:VLM設計の「何が重要か」を解き明かす
今回ご紹介する論文「What matters when building vision-language models?」では、この課題に対し、VLMの設計に関する広範な実験を行うことで「何が重要なのか」を徹底的に探求しています。
そして、その知見を集約し、Idefics2という80億パラメータを持つ、効率的で最先端のVLMを開発・公開しています。
Idefics2は、そのサイズカテゴリーにおいて様々なマルチモーダルベンチマークでState-of-the-Art (SOTA) の性能を達成しており、時には4倍の規模を持つモデルにも匹敵するという驚くべき結果を出しています。
まずは、Idefics2がどのように機能するのか、その具体的な例を見てみましょう。
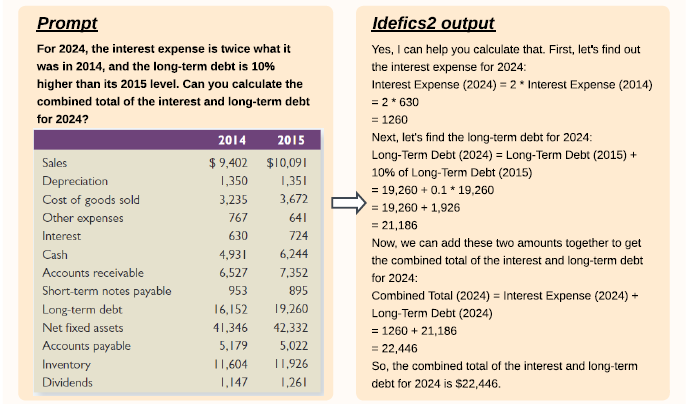
この例では、Idefics2が財務データを含む表を分析し、与えられたプロンプトに基づいて2024年の金利費用と長期負債の合計を正確に計算・回答しています。
このように、複雑な視覚情報を理解し、具体的なタスクを実行する能力は、VLMが実世界でいかに有用であるかを示しています。
Idefics2開発の背景:実験から得られた重要な発見
研究チームは、モデルアーキテクチャ、データ、トレーニング方法など、VLM構築における様々な設計選択肢について詳細な比較実験を行いました。
ここからは、彼らが特に強調している主要な発見をいくつかご紹介します。
発見1: 言語モデル(LLM)の質がVLM性能に大きく影響する
VLMは通常、既存のVisionエンコーダとLanguage Model (LLM) を組み合わせて構築されます。
研究の結果、Visionエンコーダの品質向上も重要ですが、最終的なVLMの性能に最も大きな影響を与えるのは、ベースとなるLLMの品質であることが判明しました。
例えば、より高性能なLLM(Llama-1-7BからMistral-7Bへ)に切り替えることで、VLMのベンチマークスコアが大幅に向上することが確認されました。これは、VLMの「言語」を司る部分がいかに重要であるかを示唆しています。
発見2: Fully Autoregressiveアーキテクチャの優位性
VLMのアーキテクチャには、大きく分けて「cross-attentionアーキテクチャ」と「fully autoregressiveアーキテクチャ」の2種類があります。
cross-attentionは画像情報をLLMの各層に埋め込むのに対し、fully autoregressiveはVisionエンコーダの出力をテキスト埋め込みのシーケンスに直接結合してLLMに入力します。
興味深いことに、初期の実験では、ユニモーダルなバックボーン(VisionエンコーダやLLM)を凍結して新しいパラメータのみを学習させる場合、cross-attentionアーキテクチャの方が優れた性能を示しました。
しかし、全てのパラメータを学習させる場合(LoRAなどのPEFT手法を用いることで学習の安定性を確保)、fully autoregressiveアーキテクチャがcross-attentionを上回る性能を発揮することが明らかになりました。
これは、fully autoregressiveアーキテクチャがモデル全体により高い表現力を持たせられる可能性を示唆しています。
Idefics2もこのfully autoregressiveアーキテクチャを採用しています。
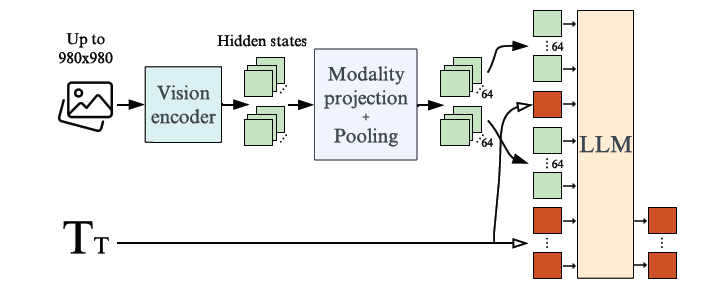
この図はIdefics2のfully autoregressiveアーキテクチャの概要を示しています。
入力画像はVisionエンコーダで処理され、得られた視覚特徴はモダリティ射影層とプーリング(要約)を経て、視覚トークンとしてLLMに入力されます。
そして、これらの視覚トークンはテキスト埋め込みのシーケンスと連結され、LLMがテキスト出力を生成します。
発見3: 推論効率の向上と画像処理の工夫
効率的なVLMを構築するためには、推論時のコストを削減する工夫も重要です。
- ビジュアルトークン数の削減: 多くのVLMは、Visionエンコーダから大量のビジュアルトークンをLLMに渡しますが、Perceiver resamplerのような学習可能なプーリング戦略を用いることで、ビジュアルトークン数を大幅に削減しつつ、性能を向上させられることが分かりました。Idefics2では、729トークンから64トークンへの削減に成功しています。
- アスペクト比と解像度の維持: 通常、Visionエンコーダは固定サイズの正方形画像で学習されますが、画像を元の形や解像度を保ったままエンコードできるようVisionエンコーダを適応させることで、性能を損なうことなく、学習および推論の計算効率を向上させることが可能です。これにより、長文のテキストを読むタスクなどで特にメリットがあります。
発見4: Compute-Performanceのトレードオフ戦略
特定のタスクにおいて性能をさらに向上させるために、計算コストとのトレードオフを許容する戦略も有効です。
例えば、画像を複数のサブイメージに分割し、それらを元の画像と合わせてLLMに与える「画像分割(image splitting)」戦略です。
この戦略は、特にTextVQAやDocVQAのような、画像内のテキスト読み取りを要求されるベンチマークで顕著な性能向上が見られました。
Idefics2では、推論時に単一の画像(64ビジュアルトークン)だけでなく、人工的に拡張された画像(合計320ビジュアルトークン)も扱えるように学習されています。
Idefics2:実践された知見が詰まったSOTA VLM
これらの多岐にわたる実験的知見を基に、Hugging Faceの研究チームはIdefics2を開発しました。
Idefics2は、SigLIP-SO400MをVisionバックボーンに、Mistral-7B-v0.1をLLMバックボーンに採用しています。
Idefics2は、以下の段階で学習されました。
- 多段階事前学習 (Multi-stage Pre-training):
- データ: OBELICS(画像とテキストが混在するウェブスケールデータセット)、高品質な画像-テキストペア(LAION COCOの合成キャプションなど)、そしてOCRデータ(PDF文書やRendered Textなど)を組み合わせて学習。
- 解像度: 最初のステージでは低解像度(最大384ピクセル)で広範な学習を行い、次のステージでPDF文書などの高解像度(最大980ピクセル)が必要なデータを導入し、より詳細な視覚理解能力を獲得。
- 学習データ量: 約15億枚の画像と2250億のテキストトークンという、他のオープンVLMをはるかに上回る規模のデータで学習されています。
- Instruction Fine-tuning:
- 「The Cauldron」と名付けられた50もの多岐にわたるVision-Languageデータセットと、テキストのみの指示データセットを組み合わせて、モデルを特定のタスクに特化させました。
- DoRA(LoRAの派生形)を活用し、NEFTuneなどの技術で過学習を抑制しながら、回答部分のみに損失を計算することで効率的な学習を実現しています。
- Chatシナリオ最適化:
- Instruction fine-tuning後、LLaVA-ConvやShareGPT4Vなどの対話データで追加学習を行い、人間が好むような、より自然で長い会話応答ができるように調整されました。
これらの工夫により、Idefics2はMMMU、MathVista、TextVQA、MMBenchなどの主要なベンチマークで、その規模のカテゴリーにおいてSOTAの性能を達成しています。
さらに、推論時には他のモデルよりもはるかに効率的でありながら、Gemini 1.5 Proのようなクローズドソースの強力なモデルにも匹敵する性能を見せています。
まとめ
本論文は、VLMの設計における長年の疑問に対し、大規模かつ厳密な実験を通じて明確な答えを与えてくれました。
特に、LLMバックボーンの質、fully autoregressiveアーキテクチャの優位性、そして効率的な画像処理戦略が、高性能VLMを構築する上で不可欠であることが示されています。
Idefics2は、これらの知見が詰まった「オープン」な80億パラメータVLMとして、モデル(base、instructed、chatバージョン)と学習データセットが公開されています。
この成果は、VLM研究コミュニティ全体の進歩を加速し、実世界の問題解決に貢献する画期的な一歩となるでしょう。