今回は、2014年のImageNet Large-Scale Visual Recognition Challenge (ILSVRC) で圧倒的な性能を示し、その後の深層学習モデルに大きな影響を与えた論文「Going deeper with convolutions」をご紹介します。
この論文は、Googleの研究者らによって発表され、画期的なアーキテクチャ「Inception」を提案しました。
arXivリンク: arXiv:1409.4842v1
はじめに:画像認識の歴史を変えた一歩
近年、画像認識や物体検出の分野では、深層学習、特に畳み込みニューラルネットワーク(CNN)の進化によって、目覚ましい進歩が遂げられています。
この進歩は、単にハードウェアの性能向上やデータセットの拡大だけでなく、新しいアイデアやアルゴリズム、そして優れたネットワークアーキテクチャから生まれています。
2014年のILSVRCでは、Googleの研究チームが提案した「GoogLeNet」というモデルが優勝し、分類および検出タスクで新たなSOTA(State of the Art、最高性能)を達成しました。
GoogLeNetは、当時としては革新的な「Inception」というアーキテクチャを採用しており、その特徴は「計算リソースの利用効率の向上」にありました。
具体的には、ネットワークの「深さ(層の数)」と「幅(各層のユニット数)」を増やすと同時に、計算コストを抑える工夫が凝らされています。これにより、従来のモデルと比較して、少ないパラメータ数で高い精度を実現しています。
ネットワークを深く・広くするだけではダメ?
深層ニューラルネットワークの性能を向上させる最も簡単な方法は、ネットワークのサイズを大きくすることです。つまり、層の数を増やしてより「深く」し、各層のユニット数を増やしてより「広く」することです。しかし、このシンプルなアプローチには2つの大きな課題があります。
1つ目は「過学習」のリスクです。ネットワークが大きくなるとパラメータ数が増え、学習データが限られている場合に過学習しやすくなります。
ImageNetのような大規模データセットであっても、シベリアンハスキーとエスキモードッグのような非常に似た犬種を区別するような「ファイングレイン」な分類は難しく、学習データの質と量が重要になります。

2つ目は「計算リソースの肥大化」です。例えば、畳み込み層を2つ重ねた場合、フィルタ数を均一に増やすと計算量が劇的に増加してしまいます。
もし、追加された容量が非効率に使われ(例えば、ほとんどの重みがゼロに近い値になる)、計算がムダになってしまうと、有限の計算予算を効率的に使うことができません。
Inceptionモジュールの登場:効率的な構造で「深み」へ
これらの課題を解決するために、Inceptionアーキテクチャは「Inceptionモジュール」という新しいビルディングブロックを提案しました。
このモジュールの核となるアイデアは、直感的なマルチスケール処理と、効率的な計算リソースの利用にあります。
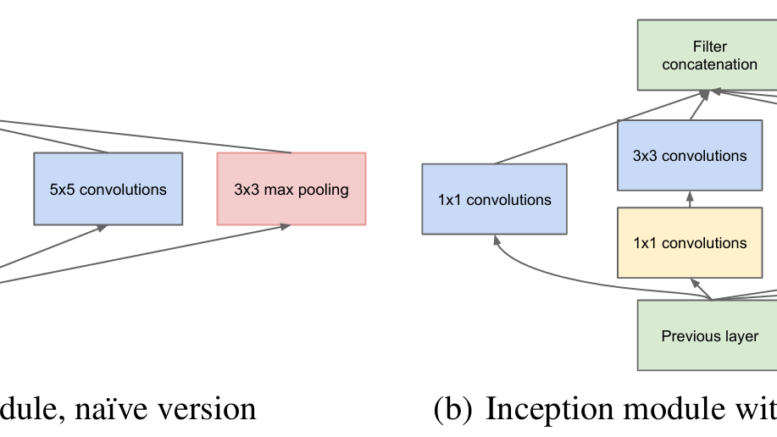
従来のCNNは、通常1種類の畳み込みフィルタサイズ(例:3×3)とMaxPoolingを層ごとに適用していました。
しかし、画像内のオブジェクトは様々なサイズで出現するため、複数のスケールで情報を処理することが重要です。
Inceptionモジュールでは、1×1、3×3、5×5といった異なるサイズの畳み込みフィルタと、MaxPoolingを並列に配置し、それぞれの出力を連結するという構造を採用しています。これにより、ネットワークは単一の層で、入力画像から様々なスケールの特徴を同時に抽出できるようになります。
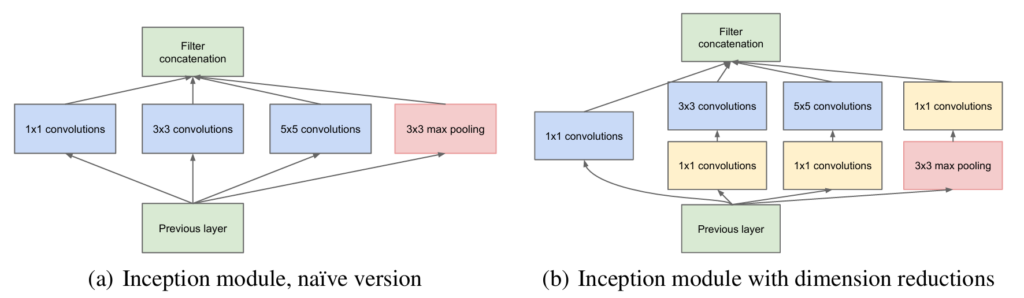
次元削減の魔法:1×1畳み込みの二重の役割
異なるフィルタの出力を単純に連結するだけでは、出力のチャネル数が急増し、次の層での計算コストが爆発的に増大するという問題が発生します。
ここでInceptionモジュールの賢い工夫が光ります。それが「次元削減」です。
Inceptionモジュールでは、高価な3×3畳み込みや5×5畳み込みを行う前に、1×1畳み込みを導入します。
この1×1畳み込みは、空間的な情報をほとんど失うことなく、チャネル数を減らす(次元削減する)役割を果たします。これにより、次の高価な畳み込みの計算量を大幅に削減し、ネットワークの深さや幅を無理なく増やすことが可能になります。
さらに、1×1畳み込みはReLU(Rectified Linear Unit)活性化関数と共に使われることで、単なる次元削減だけでなく、ネットワークの表現能力を高める「追加の非線形変換」としても機能します。
この二重の役割が、Inceptionモジュールの効率性と強力さの鍵となっています。
GoogLeNetの全体像:Inceptionモジュールが積み重なる22層
GoogLeNetは、このInceptionモジュールを基本的な構成要素として積み重ねた、深さ22層(パラメータを持つ層のみをカウント)のネットワークです。
ネットワークの入力に近い層では、従来の畳み込み層とMaxPooling層が使われますが、より深い層でInceptionモジュールが本格的に導入されます。
興味深い特徴として、GoogLeNetでは、ネットワークの途中の層にも「補助分類器」が接続されています。これは、深層ネットワークにおける勾配消失の問題に対処し、ネットワーク全体に安定した勾配信号を供給することを目的としています。これらの補助分類器は、訓練時にはメインの損失関数に寄与しますが、推論時には破棄されます。
GoogLeNetは、計算効率と実用性を重視して設計されており、限られた計算リソースを持つデバイスでも推論を実行できるように、低いメモリ使用量を念頭に置いています。
これにより、純粋な学術的な好奇心だけでなく、現実世界のアプリケーションにも適用できるような設計がなされました。
ILSVRC 2014での輝かしい成果
GoogLeNetは、ILSVRC 2014の分類タスクでトップ5エラー率6.67%という驚異的な成績で優勝しました。これは、2012年の優勝モデルと比較して約56.5%の相対的なエラー削減であり、前年のベストモデルと比較しても約40%の相対的な削減となります。
特筆すべきは、GoogLeNetが2年前の優勝モデルと比較して、約12分の1のパラメータ数で、かつ大幅に高い精度を達成した点です。
これは、ただネットワークを大きくするのではなく、効率的なアーキテクチャの設計が性能向上にいかに重要であるかを示しています。
また、物体検出タスクにおいても、GoogLeNetはR-CNNなどの既存手法と組み合わされることで、43.9%のmAP(mean Average Precision)を達成し、これも優勝に貢献しました。
複数のモデルを組み合わせる「アンサンブル学習」や、多様な領域を切り出して評価する「アグレッシブなクロッピング」も、最終的な性能向上に大きく貢献しています。
まとめ:深層学習の新たな道を切り拓いたInception
「Going deeper with convolutions」で提案されたInceptionアーキテクチャは、深層学習における効率的なネットワーク設計の重要性を明確に示しました。
スパースな(まばらな)接続構造という理想を、既存の密な計算ブロックを組み合わせて近似するというアプローチは、計算要件を控えめに抑えながら、顕著な品質向上をもたらしました。
Inceptionの成功は、単に計算パワーで押し切るだけでなく、より洗練されたアーキテクチャの探求が、深層学習の未来を形作ることを示唆しています。
この論文は、その後のInception v2, v3, v4といった進化版や、他の効率的なネットワーク設計手法にも大きな影響を与え、深層学習研究の方向性を大きく変える一歩となりました。