
本日は、2017年の国際会議CVPRで発表され、画像認識の分野に大きな影響を与えた論文「Mask R-CNN」をご紹介します。
この論文は、Facebook AI Research (FAIR)のKaiming He氏らが発表したもので、インスタンスセグメンテーションというタスクにおいて、シンプルかつ柔軟、そして非常に強力なフレームワークを提案しました。
インスタンスセグメンテーションとは?
まず、インスタンスセグメンテーションという言葉に馴染みがない方もいらっしゃるかもしれません。画像認識にはいくつかの主要なタスクがあります。
例えば、「物体検出」は、画像の中にある物体を長方形の枠(バウンディングボックス)で囲み、それが何であるかを分類するタスクです。リンゴがいくつあるかを数えるようなイメージです。
一方で「セマンティックセグメンテーション」は、画像中の全てのピクセルを、それが属するカテゴリ(例:空、道路、建物、人など)に分類するタスクです。これは、各ピクセルにラベルを付けることで、画像全体の意味を理解することを目指します。

「インスタンスセグメンテーション」は、これら二つのタスクを組み合わせたものです。単に「人」というカテゴリのピクセルを全て分類するだけでなく、画像内にいる「一人ひとりの人」を個別のインスタンスとして識別し、それぞれをピクセル単位で正確に切り分けることを目指します。例えば、重なり合っている複数のリンゴを、それぞれ別々のリンゴとして正確に輪郭を検出するようなイメージです。
Mask R-CNNの登場
インスタンスセグメンテーションは、物体検出とセマンティックセグメンテーションの両方の難しさを含むため、非常に挑戦的なタスクでした。しかし、Mask R-CNNは、既存の強力な物体検出フレームワークであるFaster R-CNNを基盤として、この課題に驚くほどシンプルに、かつ高い精度で取り組みました。
Mask R-CNNの基本的なアイデアは、Faster R-CNNが提供する「物体のクラス分類」と「バウンディングボックスの回帰」という2つの出力に、「オブジェクトのマスクを予測する3つ目のブランチ」を追加するというものです。これにより、物体を検出しながら、同時にその物体の高品質なセグメンテーションマスクを生成することが可能になりました。
Mask R-CNNを支える2つの重要な技術
Mask R-CNNが高い性能を達成できた背景には、特に二つの重要な技術革新があります。
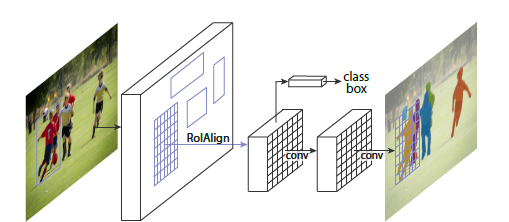
RoIAlign層の導入
従来のFaster R-CNNなどのモデルでは、Region of Interest(RoI:検出候補領域)から特徴を抽出する際に「RoIPool」という操作が使われていました。しかし、このRoIPoolは、特徴マップ上の座標を整数に「量子化」する際に、微細な位置情報が失われてしまうという問題がありました。
物体検出のように大まかなバウンディングボックスを予測するタスクでは問題になりにくかったこの「位置ずれ」が、ピクセル単位で正確なマスクを生成するインスタンスセグメンテーションでは致命的な問題となります。
Mask R-CNNは、この問題を解決するために「RoIAlign」という新しい層を提案しました。RoIAlignは、RoIの境界や区画の量子化を一切行わず、双線形補間(bilinear interpolation)を使って正確な特徴値を計算します。これにより、RoIと抽出された特徴との間の位置ずれが解消され、マスクの精度が大幅に向上しました。論文中では、この一見小さな変更がマスク精度を10%から50%も向上させたと報告されています。
マスクとクラス予測の分離
セマンティックセグメンテーションでは、通常、各ピクセルがどのカテゴリに属するかを競合的に予測する「多項分類(softmax)」が用いられます。しかし、Mask R-CNNは、これとは異なるアプローチを採用しました。
まず、Faster R-CNNのバウンディングボックス予測ブランチが、そのRoIが何のクラスであるかを決定します。
その後、マスク予測ブランチは、各クラスに対して独立してバイナリマスク(0か1でピクセルを分類)を生成します。つまり、「これは犬か?」という問いに対して「はい/いいえ」で答えるように、各クラスごとに「このピクセルは、このクラスの物体の一部か?」という質問に答えるようなイメージです。
この「マスクとクラス予測の分離(decoupling)」により、各マスクは他のクラスと競合することなく、そのクラスの物体の形状に集中して予測できるようになります。このシンプルな分離が、インスタンスセグメンテーションの精度を大きく向上させる鍵となりました。
幅広い応用と高速な性能
Mask R-CNNは、そのシンプルさと強力さから、COCOチャレンジという大規模な画像認識コンペティションのインスタンスセグメンテーション、物体検出、人物キーポイント検出の3つのトラックすべてでトップの結果を達成しました。特に、人物キーポイント検出では、各キーポイントを「1つのピクセルからなるマスク」として扱うことで、既存の複雑な手法を上回る精度を達成しています。

これは、Mask R-CNNが単一のタスクに特化したモデルではなく、インスタンスレベルの認識タスク全般に適用できる汎用的なフレームワークであることを示しています。
さらに、Mask R-CNNは、GPU上で1フレームあたり約200msという高速な推論速度を誇り、COCOデータセットでの学習も数日で完了します。この高速な学習・推論速度と高い精度、そして柔軟性は、インスタンスセグメンテーション分野における今後の研究を大いに加速させることでしょう。
まとめ
Mask R-CNNは、以下の重要な要素によってインスタンスセグメンテーションの分野に革命をもたらしました。
- Faster R-CNNをベースにしたシンプルかつ効果的なアーキテクチャ。
- ピクセルレベルの正確なアライメントを実現するRoIAlign層。
- マスクとクラス予測を分離することで、モデルの学習を容易にし、精度を向上。
- インスタンスセグメンテーション、物体検出、人物キーポイント検出など、幅広いタスクに対応する汎用性。
この研究は、概念的にはシンプルでありながら、その強力な性能と汎用性で、画像認識コミュニティにおけるインスタンスレベルの認識研究の強力なベースラインとして機能し続けています。オープンソースのコードも公開されており、多くの方に活用されています。