本記事では、3Dシーン表現と新規視点合成の分野に革新をもたらした画期的な研究「NeRF (Neural Radiance Fields)」について、初心者の方にも分かりやすく解説します。
論文タイトル: “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”
arXivリンク: arXiv:2003.08934v2
はじめに:View Synthesisの課題
「View Synthesis(視点合成)」とは、既存の複数の画像から、これまで撮影されていない新しい視点からの画像を生成する技術のことです。例えば、いくつかの角度からリンゴを撮影した写真があったとして、それらの写真からまだ誰も見ていない角度からのリンゴの写真をAIが作り出す、といったイメージです。
しかし、現実世界の複雑なシーン、例えば光沢のある表面や細かい凹凸を持つオブジェクトを含むシーンをリアルに表現し、あらゆる視点から一貫した高品質な画像を生成するのは非常に難しい課題でした。
これまでの手法では、シーンをボクセルグリッド(3Dのピクセルのようなもの)やメッシュとして表現することが多かったのですが、これらは解像度を上げるとストレージコストが膨大になったり、細かいディテールを滑らかに表現しきれなかったりするという課題がありました。
そんな中、Googleの研究チームが発表した「NeRF (Neural Radiance Fields)」は、この課題に対して全く新しい、そして非常に効果的なアプローチを提示し、SOTA (State-of-the-Art) を達成しました。
NeRFとは? シーンを「連続関数」として表現する
NeRFの最も核心的なアイデアは、「シーン全体を一つの連続的な5次元関数として表現する」というものです。この関数は、MLP(MultiLayer Perceptron:多層パーセプトロン、シンプルなニューラルネットワークの一種)によって学習されます。
具体的には、空間上のあらゆる3D位置 (x,y,z) と、そこからどの方向 (θ,φ) を見るか、という5つの情報 (x,y,z,θ,φ) をニューラルネットワークに入力します。すると、そのニューラルネットワークは、その位置・方向での「色 (RGB)」と、その位置の「体積密度 (σ)」を出力します。
体積密度は、その場所で光がどれだけ遮られるか、あるいはどれだけ光を放出するかを表す、いわば「微分的な不透明度」のようなものです。このMLPを最適化することで、シーンの形状と、光沢などの視点に依存する複雑な見た目の両方を、連続的に表現できるようになります。
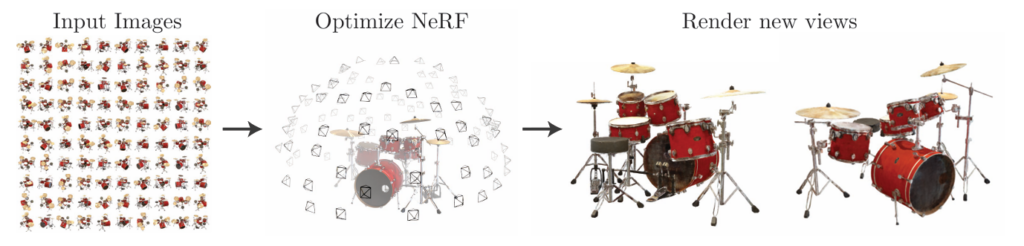
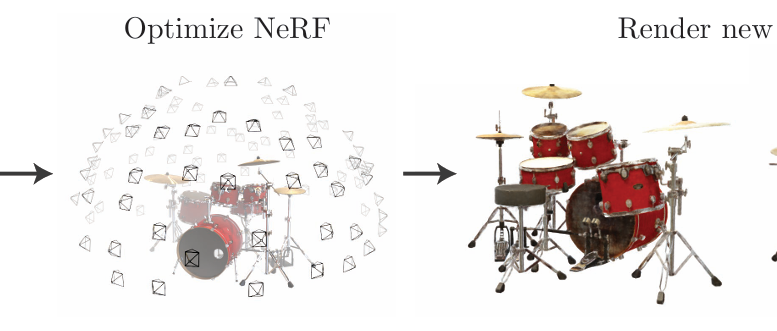
上の画像はNeRFの学習データとなるドラムセットとその撮影カメラ位置の例で、様々な視点から撮影された写真が学習に用いられます。
NeRFの仕組み:新規視点画像生成のプロセス
NeRFを使って新しい視点からの画像を生成するプロセスは、以下のステップで進められます。
- カメラレイのサンプリング: まず、仮想カメラから各ピクセルを通る「レイ(光線)」をシーンに飛ばします。それぞれのレイに沿って、いくつかの3Dポイントをサンプリングします。
- MLPによる色と密度の予測: サンプリングされた各3Dポイントについて、その位置情報と、レイの視線方向をMLPに入力します。MLPは、そのポイントでの色(RGB値)と体積密度(σ値)を出力します。
- ボリュームレンダリング: これらの色と密度の情報を、古典的な「ボリュームレンダリング」という技術を使って合成します。これにより、レイに沿って光がどのように透過し、蓄積されていくかをシミュレートし、最終的なピクセルの色を計算します。
- 最適化: このレンダリングプロセスは全て微分可能であるため、NeRFはレンダリングされた画像と実際の入力画像との間の誤差を最小化するように、MLPの重みを学習(最適化)できます。これにより、ニューラルネットワークは、複数の視点から見て一貫性のあるシーンのモデルを自律的に構築するのです。
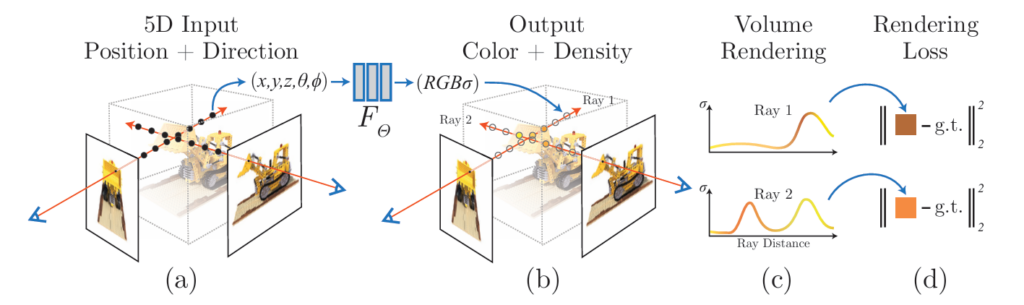
NeRFのレンダリングおよび学習パイプラインの概要。カメラレイに沿って5D座標をサンプリングし、MLPで色と密度を予測、ボリュームレンダリングで画像を合成し、その誤差を元にMLPを最適化します。
NeRFがすごい理由:高精度な表現を可能にする工夫
初期のシンプルなMLPベースのシーン表現は、しばしば高周波なディテール(細かい模様やシャープなエッジなど)の表現が苦手でした。NeRFは、この問題を解決するために二つの重要な工夫を導入しています。
1. 位置エンコーディング (Positional Encoding)
MLPは、低周波の関数(なめらかな変化)を学習しやすいという特性があります。しかし、リアルなシーンには、木の葉の質感や水面のさざ波、オブジェクトの鋭いエッジなど、高周波のディテールが豊富に含まれています。
NeRFでは、入力される3D位置や視線方向の座標を、sin関数やcos関数などの高周波成分を含む形式に変換してからMLPに渡します。これを「位置エンコーディング」と呼びます。
この処理により、MLPは高周波な情報をより効率的に学習できるようになり、結果として非常にシャープでリアルな幾何学的構造やテクスチャの表現が可能になりました。
2. 階層的ボリュームサンプリング (Hierarchical Volume Sampling)
レイに沿って均等に多くの点をサンプリングすると、シーン内容に寄与しない「空の空間」や「完全に遮蔽された領域」まで計算することになり、非常に非効率です。
NeRFは、この非効率性を改善するため、「粗い」ネットワークと「細かい」ネットワークの二段階の階層的なサンプリング戦略を提案しました。
まず、「粗い」ネットワークで大まかな密度分布を予測し、その結果に基づいて、より重要な領域(光が遮られたり、色が変わったりする可能性が高い場所)にサンプルを集中させて「細かい」ネットワークで処理します。
この戦略により、必要なサンプル数を大幅に削減しつつ、高解像度のシーン表現を効率的に実現しています。
他の手法との比較とNeRFの優位性
NeRFは、他の最先端のView Synthesis手法と比較しても、その性能において優位性を示しています。特に、詳細なジオメトリや複雑な素材(光沢のある表面など)を、非常に高いフォトリアリスティックな品質でレンダリングできる点が評価されています。
また、既存のボクセルベースの手法が、解像度を上げると膨大なストレージを必要とするのに対し、NeRFはMLPの重み(数MB程度)のみでシーンを表現するため、メモリ効率も非常に高いという利点があります。これは、シーン表現の根本的なアプローチの違いからくる大きなメリットと言えるでしょう。
まとめ
NeRFは、3Dシーンを「ニューラルネットワークによって学習される連続的な5次元関数」として表現するという、シンプルかつ強力なアプローチで、View Synthesisの分野に大きな進歩をもたらしました。
位置エンコーディングや階層的サンプリングといった工夫により、高周波なディテールや視点依存の複雑な見た目もリアルに再現できるようになり、限られた数の入力画像からフォトリアリスティックな新規視点画像を生成する能力は目覚ましいものがあります。
この技術は、VR/ARコンテンツ制作、3Dモデリング、コンピュータビジョンなど、様々な分野に応用される可能性を秘めています。NeRFとその派生研究は、今後も3DグラフィックスとAIの融合を加速させていくことでしょう。