本日は、2015年にKaiming HeらMicrosoft Researchの研究者によって発表された画期的な論文「Deep Residual Learning for Image Recognition」についてご紹介します。
この論文で提案された「ResNet(Residual Network)」は、深層学習の「深さ」を飛躍的に拡大し、その後の画像認識分野に多大な影響を与えました。
この論文はarXivで公開されています: arXiv:1512.03385v1
また、この研究はILSVRC 2015の画像分類タスクで1位を獲得したほか、ImageNet検出、ImageNet局所化、COCO検出、COCOセグメンテーションといった複数のコンペティションでも1位に輝いています。
深層学習における「深さ」の重要性
近年のディープラーニングのブレークスルーは、ネットワークの「深さ」に大きく依存しています。畳み込みニューラルネットワーク(CNN)は、層を深くすることで低レベルから高レベルの多様な特徴を学習し、画像認識の精度を向上させてきました。
しかし、単純に層を深くするだけでは、学習が非常に困難になるという問題に直面していました。かつては「勾配消失・爆発問題」が主な原因とされていましたが、正規化手法(Batch Normalizationなど)や適切な初期化によって、この問題はある程度解決されました。
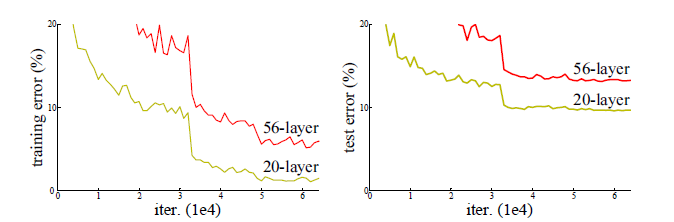
それでもなお、ネットワークを深くすると、精度が頭打ちになり、さらには「劣化(degradation)」するという現象が見られました。これは、訓練誤差(training error)ですら、浅いネットワークよりも深いネットワークの方が高くなるという、直感に反する現象でした。
「劣化問題」の正体
この「劣化問題」は、単なる過学習(overfitting)とは異なります。過学習であれば、訓練誤差は低いがテスト誤差が高いという状態になりますが、劣化問題では訓練誤差自体も高くなってしまうのです。
理論的には、深いネットワークは浅いネットワークの「恒等写像(identity mapping)」を学習することで、少なくとも浅いネットワークと同等かそれ以上の性能を発揮できるはずです。つまり、追加された層が何もしない(入力と同じ値をそのまま出力する)ように学習されれば良い、ということです。
しかし、実際の最適化アルゴリズム(SGDなど)は、この「恒等写像」を多層の非線形層で近似することに苦労していることが示されました。
ResNetの核心:Residual Learning
この劣化問題を解決するために、ResNetが導入したのが「Residual Learning(残差学習)」というフレームワークです。
従来のネットワークが、入力 x から直接目的の写像 H(x) を学習しようとするのに対し、ResNetでは、層が学習するべき写像を「残差関数 F(x) = H(x) - x 」として再定義します。
つまり、ネットワークは H(x) そのものではなく、H(x) と x の差分を学習するのです。そして、最終的な出力は F(x) + x となります。
このアイデアの仮説は、「残差写像 F(x) を最適化する方が、元の写像 H(x) を最適化するよりも容易である」というものです。極端な話、もし最適な写像が恒等写像 H(x) = x であった場合、F(x) はゼロに近づけばよいことになります。多層の非線形層で恒等写像そのものを学習するよりも、F(x) をゼロに近づける方が簡単だ、というわけです。
ショートカット接続による実装
このResidual Learningは、「ショートカット接続(shortcut connection)」と呼ばれるシンプルな構造によって実現されます。ショートカット接続は、一つ以上の層をスキップして、その出力をスタックされた層の出力に「要素ごとの加算(element-wise addition)」で加えるものです。
ResNetでは、このショートカット接続が恒等写像として機能します。つまり、入力 x は、学習する残差関数 F(x) の出力にそのまま加算されるのです。
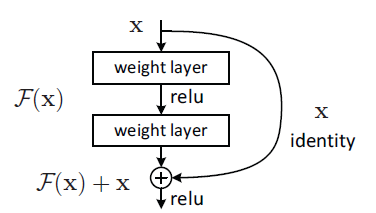
上の図のような、入力 x が2層のレイヤーブロックを通り F(x) となり、元の x と加算されて F(x) + x となるような、Residualブロックの概念図をイメージしてください。
この恒等ショートカット接続は、追加のパラメータや計算量を必要としません。そのため、PlainネットワークとResNetを公平に比較することができ、Residual Learningの有効性を純粋に評価できます。次元が異なる場合(チャンネル数が変わるなど)は、1x1 畳み込みを用いた線形射影(projection shortcut)で次元を合わせることもありますが、恒等ショートカットでも十分に効果があることが示されています。
ResNetのアーキテクチャ例
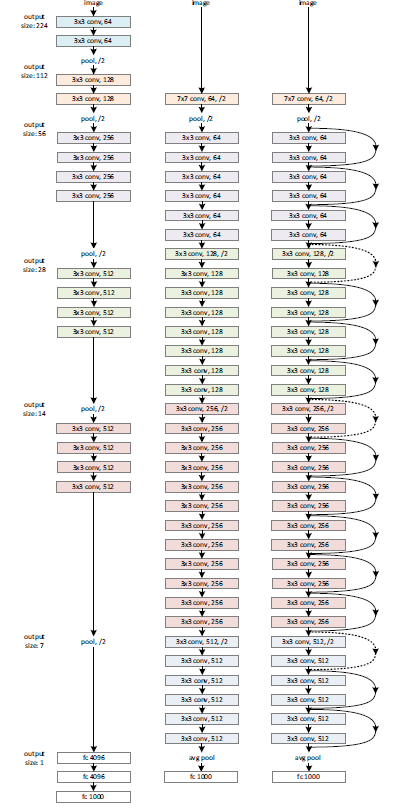
ResNetは、VGGネットの設計思想を参考に、3x3 フィルタを主に用いて構築されます。特徴マップのサイズが半分になる際には、フィルタ数を倍にして計算量を保つように設計されています。
特に深いResNetでは、計算効率を高めるために「ボトルネック(bottleneck)」デザインが導入されます。これは、1×1畳み込みで次元を削減し、3×3畳み込みのボトルネック層を挟み、再び1×1畳み込みで次元を復元するという3層構造のブロックです。これにより、より深いネットワークを効率的に構築できます。
驚異的な実験結果
ResNetは、ImageNetデータセットでその真価を発揮しました。152層のResNetは、従来のVGGネットワーク(16層や19層)よりもはるかに深いにもかかわらず、計算量はVGG-16/19よりも低いという効率性を実現しています。
ImageNetでの評価では、34層のPlainネットワークが18層のPlainネットワークよりも高い訓練誤差を示したのに対し、ResNetでは34層のものが18層のものよりも精度が向上し、訓練誤差も低下しました。これは、Residual Learningが「劣化問題」を見事に解決し、深さによる精度向上を可能にしたことを明確に示しています。
さらに、CIFAR-10データセットでは、100層、さらには1000層を超えるネットワークの学習に成功しました。特に110層のResNetは、他のSOTAモデルと比較しても少ないパラメータで高い精度を達成しています。
また、ResNetのレイヤー応答の標準偏差は、Plainネットワークよりも小さいことが示されました。これは、学習された残差関数が一般的にゼロに近い値を持つという、Residual Learningの基本的な動機を裏付ける結果です。
画像認識だけでなく、PASCAL VOCやMS COCOといった物体検出タスクにおいても、ResNetは大幅な性能向上をもたらしました。COCOデータセットでは、mAP@[.5, .95](COCOの標準的な評価指標)で6.0%の絶対的改善、相対的には28%もの改善を達成しています。
まとめ
「Deep Residual Learning for Image Recognition」は、ディープラーニングの歴史において非常に重要な論文です。
- 「劣化問題」の発見と解決: 単に層を深くするだけでは訓練誤差すら悪化するという、それまでの常識を覆す問題を発見し、解決策を提示しました。
- 「Residual Learning」というシンプルかつ強力なアイデア: 目的の写像そのものではなく、入力との「残差」を学習するという直感的なアイデアが、超深層ネットワークの学習を可能にしました。
- 「ショートカット接続」による効率的な実装: 追加パラメータや計算量をほとんど増やさずに、このアイデアを実現しました。
ResNetは、その後の様々な深層学習モデルの基礎となり、画像認識だけでなく多岐にわたるAI分野の発展に貢献し続けています。