
本記事では、動画と画像の両方に対応する汎用的なセグメンテーションモデル「SAM 2」についてご紹介します。
Metaから発表されたこのモデルは、既存のSegment Anything Model (SAM) をさらに進化させ、動画内のあらゆるオブジェクトをプロンプトベースでセグメンテーションする新しい能力を提案しています。
論文タイトル: SAM 2: Segment Anything in Images and Videos
arXiv: arXiv:2408.00714v2
はじめに
Segment Anything (SA) は、画像におけるプロンプト可能なセグメンテーションのための基盤モデルとして大きな注目を集めました。
しかし、現実世界は静的な画像だけでなく、複雑な動きを伴う動画で構成されています。AR/VR、ロボティクス、自動運転、動画編集といった多くの重要なアプリケーションでは、画像レベルのセグメンテーションを超えた時間的な位置特定が必要とされます。
これまでの動画セグメンテーションモデルやデータセットでは、「動画内のあらゆるものをセグメンテーションする」というSAMのような包括的な能力を提供するまでには至っていませんでした。
SAM 2は、この課題を解決するために、画像と動画の両方に対応する統一されたセグメンテーションシステムとして開発されました。
SAM 2の概要
SAM 2は、Promptable Visual Segmentation (PVS) タスクという、画像セグメンテーションを動画領域に一般化した新しいタスクを導入しています。
このタスクでは、動画内の任意のフレームに対して、点、ボックス、またはマスクといったプロンプト(指示)を与え、関心のあるセグメントの時空間マスク(masklet)を予測します。予測されたmaskletは、追加のフレームでプロンプトを提供することで、繰り返し洗練させることが可能です。
SAM 2のモデルは、Transformerベースのシンプルなアーキテクチャを採用しており、リアルタイムの動画処理のためにストリーミングメモリを備えています。
これにより、動画フレームを一度に1つずつ処理し、過去の予測やプロンプトの情報を記憶として利用することで、オブジェクトの追跡と修正を効果的に行います。
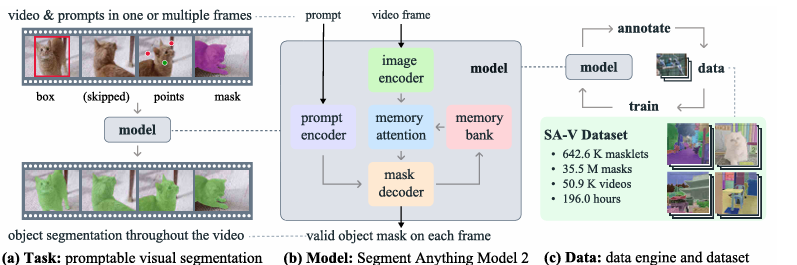
論文”SAM 2: Segment Anything in Images and Videos”より引用
モデルの学習には、ユーザーとのインタラクションを通じてモデルとデータが改善される「データエンジン」を活用し、史上最大規模の動画セグメンテーションデータセット「SA-V」を収集しました。
SA-Vデータセットは、50.9Kの動画にまたがる3,550万のマスクを含み、既存のどの動画セグメンテーションデータセットよりも53倍も多くのマスクを保有しています。
Promptable Visual Segmentation(PVS)タスクとは
PVSタスクは、動画内の任意のフレームでモデルにプロンプトを提供できる点が特徴です。プロンプトは、肯定/否定のクリック、ボックス、またはマスクのいずれかであり、セグメンテーションするオブジェクトを定義したり、モデルが予測したセグメンテーションを修正したりするために使用されます。
ユーザーが特定のフレームにプロンプトを提供すると、モデルはそのフレームでのセグメンテーションマスクを即座に返し、さらに動画全体でオブジェクトのmaskletを伝播(追跡)します。モデルがオブジェクトを見失ったり、誤りを犯したりした場合は、追加のフレームで修正クリックを提供することで、簡単に正しい予測を回復できます。
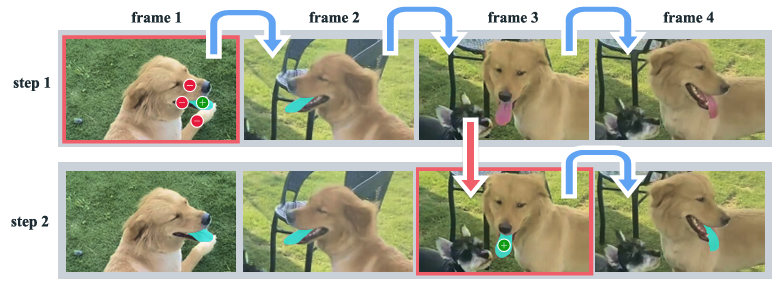
舌を追跡し、モデルが誤った際にクリック一つで修正できる
論文”SAM 2: Segment Anything in Images and Videos”より引用
このインタラクティブな特性は、以前のSAM +動画トラッカーのアプローチとは異なります。
従来の方式では、モデルがオブジェクトを見失うと、そのフレームで最初からセグメンテーションをやり直す必要があり、多くのクリックを必要としました。
しかし、SAM 2はメモリを活用することで、単一のクリックでオブジェクトを回復できるため、非常に効率的です。
SAM 2のアーキテクチャ
SAM 2は、SAMのアーキテクチャを動画領域に拡張した形をしています。基本的な構造はTransformerベースであり、以下の主要なコンポーネントで構成されています。
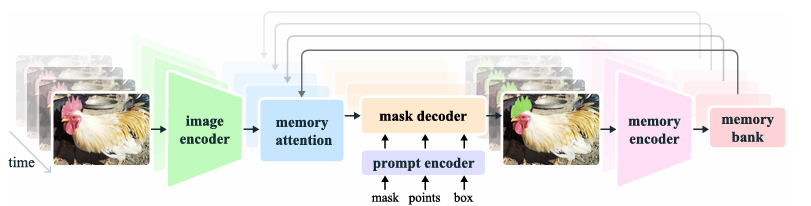
SAM 2のアーキテクチャ、論文”SAM 2: Segment Anything in Images and Videos”より引用
- Image Encoder: 各フレームのフィーチャ埋め込みを生成します。SAM 2では、MAEで事前学習されたHiera Image Encoderを使用しており、リアルタイム処理のためにストリーミングアプローチを採用しています。
- Memory Attention: 現在のフレームのフィーチャを過去のフレームのフィーチャ、予測、および新しいプロンプトで条件付けする役割を担います。
- Prompt EncoderとMask Decoder: Prompt EncoderはSAMと同様に、クリック、ボックス、マスクなどのプロンプトを処理します。Mask Decoderは、SAMの設計を概ね踏襲しつつ、階層的なImage Encoderからの高解像度埋め込みを利用するスキップコネクションや、オブジェクトの存在を予測するオクルージョン予測ヘッドが追加されています。
特に重要なのが、動画の時系列的な情報を保持する「メモリ」の存在です。このメモリは、過去の予測とインタラクションに関する情報を格納し、動画全体でmasklet予測を生成し、以前に観測されたオブジェクトの記憶コンテキストに基づいて予測を効果的に修正することを可能にします。
大規模データセット「SA-V」の構築
「あらゆるものをセグメンテーションする」というSAM 2の能力を実現するため、研究チームは大規模で多様な動画セグメンテーションデータセット「SA-V」を構築しました。
データセットの収集には、アノテーターがモデルと協調してインタラクティブに新しいデータや難しいデータをアノテーションする「データエンジン」という仕組みが用いられました。
データエンジンは3つのフェーズを経て進化しました。
- Phase 1: SAM per frame
- 初期段階では、画像ベースのSAMを使って各フレームのマスクを手動でアノテーションしました。時間効率は低いものの、高品質な空間アノテーションが得られました。
- Phase 2: SAM + SAM 2 Mask
- SAM 2を導入し、マスクプロンプトを受け付けるようにしました。アノテーターは最初のフレームでマスクを生成し、SAM 2が他のフレームに伝播します。必要に応じてSAMで修正し再伝播する方式で、アノテーション時間はPhase 1より約5.1倍高速化しました。
- Phase 3: SAM 2
- 完全に機能するSAM 2を導入し、点やマスクなど多様なプロンプトを受け入れるようになりました。SAM 2のメモリ機能により、アノテーターは予測されたmaskletを修正するために、時折の修正クリックを提供するだけで済み、効率が大幅に向上しました。これにより、アノテーション時間はPhase 1より約8.4倍高速化しました。

手動および自動でアノテーションされたmaskletが重ねて表示されている
論文”SAM 2: Segment Anything in Images and Videos”より引用
SA-Vデータセットは、50.9Kの動画と642.6Kのmaskletから構成され、総マスク数は3,550万に達します。これは既存のどのVOSデータセットよりもはるかに大規模であり、小オブジェクトや部分的なオブジェクト、オクルージョン(遮蔽)や再出現を含む難しいシナリオも豊富に含んでいます。
また、地理的にも多様な動画が収録されており、公平性評価も実施されています。
実験結果
SAM 2は、様々なゼロショット(事前学習なし)の動画および画像タスクにおいて、既存の手法と比較して優れた性能を示しています。
- プロンプト可能動画セグメンテーション:
- SAM 2は、SAM+XMem++やSAM+Cutieといった既存の最先端手法を、オフラインおよびオンラインの両方の評価設定で上回りました。
- 平均で3分の1以下のインタラクション数で、より高いセグメンテーション精度を達成しています。
- 半教師あり動画オブジェクトセグメンテーション (VOS):
- クリック、ボックス、またはマスクのプロンプトを最初のフレームにのみ与える従来のVOS設定においても、SAM 2は17のデータセットで既存のベースラインを凌駕しました。
- これは、SAM 2が汎用的なプロンプトベースのセグメンテーションだけでなく、従来のVOSタスクでも優れた性能を発揮できることを示しています。
- 画像セグメンテーション:
- SAM 2は、37のゼロショットデータセット(SAMが以前評価に使用した23のデータセットを含む)で評価され、SAMよりも高い精度を達成し、かつ6倍高速でした。
- これは、Hiera Image Encoderの効率性が大きく貢献しています。
SAM 2の限界
SAM 2は静止画と動画の両方で強力な性能を発揮しますが、いくつかの課題も存在します。
- ショットの変化、混雑したシーン、長時間のオクルージョン、長尺動画: これらにおいては、オブジェクトの追跡を見失ったり、混同したりする可能性があります。ただし、任意のフレームでプロンプトを与えて修正できる機能があるため、エラーを迅速に回復できます。
- 非常に細い、または細かい詳細を持つオブジェクトの追跡: 特に高速に移動するオブジェクトの場合、正確な追跡が困難な場合があります。
- 類似した外観を持つ近くのオブジェクト: 例えば、複数の同一のジャグリングボールなど、モデルがオブジェクトを混同する可能性があります。より明示的な動きのモデリングを導入することで、これらのエラーを軽減できる可能性があります。
- 複数オブジェクトの同時追跡: SAM 2は個々のオブジェクトを独立して処理するため、オブジェクト間の共有コンテキスト情報を活用することで、効率性をさらに改善できる可能性があります。
まとめ
本記事では、Metaによって発表された基盤モデル「SAM 2」について解説しました。SAM 2は、Segment Anything Model (SAM) を動画領域に自然に進化させたものであり、以下の3つの主要な要素に基づいています。
- プロンプト可能セグメンテーションタスクの動画への拡張。
- SAMアーキテクチャへのメモリの搭載による動画処理能力の強化。
- 動画セグメンテーションの学習とベンチマークのための多様なSA-Vデータセットの構築。
これらの貢献により、SAM 2は動画セグメンテーションと関連する知覚タスクにおける重要なマイルストーンとなるでしょう。将来的には、さらなる研究とアプリケーションの進展を推進する可能性を秘めています。