
Tensorflow+Kerasの環境構築を前回やってみて、無事環境構築に成功しました。
そのときはMNISTデータセットで正常な実行を確認しましたが、実用的な面を考えると、自分で学習画像を用意して訓練するというケースが多くなると思います。
そこで、予めフォルダに分類した学習画像からクラス名(及びクラス数)を自動で読み取り、各クラスの分類学習を行うソースコードを書いてみました。
また、前回からの差分として、分類のモデルはAlexNet(畳み込み層5層、全結合層3層モデル)を用いることとしました。
AlexNetのモデル部分のコードに関しては、
参考ページ:KerasによるAlexNetを用いた犬猫分類モデル – Qiita
上記のコードを参考にさせていただきました。ありがとうございます(厳密には上記のコードはLRNがBN((Batch Normalization)に変わっているので、AlexNetの論文実装とは異なっています)。
今回の環境
・OS : Windows10(64bit)
・GPU: GeForce GTX 950
・Anaconda
・CUDA 9.0
・cuDNN v7.0.5
・Tensorflow 1.11.0
・Keras 2.2.4
上記全て環境構築済
ソースコード
先にソースコードを載せちゃいます。説明は先を読んでください。
使用するデータセットと準備
今回は自作画像……といいつつ、自作画像を用意するのは面倒なので、JPGやPNGなどの一般的な画像形式で提供されている公開データセットを使うことにしました。
ただ、今回のソースコードに関しては、自分で学習画像を収集して、フォルダに分類し、そのフォルダ名をソースコード内に入れるだけで使っていただけるような構成になっています。
では、今回のソースコードを動かすためのデータセットの準備方法を説明します。
今回、「animeface-character-dataset」というアニメキャラの顔画像のデータセットを使用しています。以下のページからダウンロード可能です。
外部サイト:animeface-character-dataset
ダウンロードしたZIPファイルを解凍すると、以下のように各キャラクター別に分類された画像が入ったフォルダ群が展開されます。
多数のキャラクターがあるのですが、学習にあまり時間を掛けたくないという事情から、10キャラ分のフォルダだけを、訓練データ配置用のフォルダへ移動します。
訓練データ配置用のフォルダに関してはソースコードの方から変更可能ですが、私は実行ファイルからの相対パスで見て「..\\training_dataset\\training_anime1」のフォルダに画像を置きました。
あとは、ソースコードの29-35行目に訓練データ配置フォルダへのパスと、各クラスごとの画像が入ったフォルダ名を指定して、認識を行うことができます。
コードの説明
一部コードをかいつまんで説明します。
カラー画像とグレースケール画像への対応
今回は最初の方でCOLOR_CHANNELという変数を定義し、これを1のときは画像をグレースケールとしてネットワークへ入力、3のときはカラー画像としてネットワークに入力できるようにしました。
以下の部分のコードにて、 グレースケール入力とカラー入力を自動で切り替えるようにしています。入力が元々グレースケールだとカラーで入れても意味がない気がしますが、元々カラー画像で用意されている場合は、グレースケールに変換して入力してくれます。
また、ネットワークの入力の部分にも、COLOR_CHANNELを変数として与えて、グレースケールとカラーの場合で入力の形が自動で変わるようにしています。
分類クラス数の自動取得
今回は10人のキャラクターの顔を分類するので、当然クラスは10になります。
フォルダごとに分類した学習画像を用意すれば、クラス数はフォルダ数と同一になるため、以下のようにフォルダ数から自動でクラス数をカウントし、
ネットワークの出口のところの数はクラス数に合わせないとエラーが起こります。
実行結果の確認
結構画像数の少ないデータセットなので、少々実験としては心許ない部分がありますが、実際に実行をしてみました。
今回はカラーチャンネルを変更し、グレースケール化した訓練画像で認識する場合と、カラー化した訓練画像で認識する場合を比較してみましょう。
エポックは100、バッチサイズは32で統一しました。
COLOR_CHANNEL = 1 の結果
COLOR_CHANNEL = 1でプログラムを回したところ、以下のような結果が出ました。
上の190は検証に用いた画像の枚数で、Lossは損失を示し、低ければ低いほど良い結果であることを示します。
そして、肝心の精度は81.6%というところでした。

今回は10クラス分類なので、ランダムで正解当てをした場合は精度は10%ですが、81.6%とモデルの訓練が成功していることがわかります。
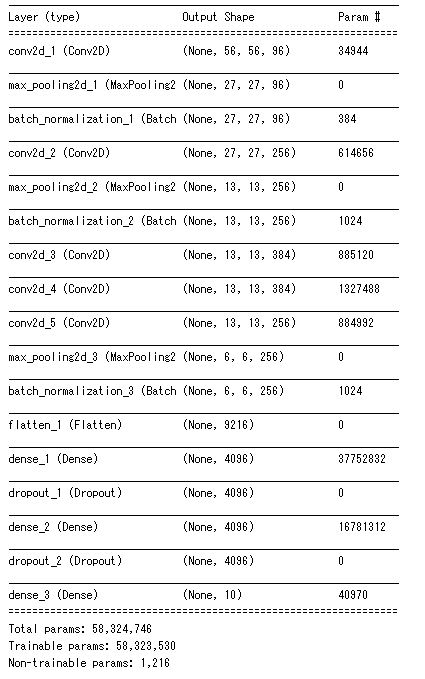
また、以下がsummary()関数で表示したモデルの構成です。
COLOR_CHANNEL = 3 の結果
次に、COLOR_CHANNELを3に変えて実験をしました。
結果は以下となりました。

精度は88.4%と、グレースケールの場合よりも精度が高まりました。
これは、アニメのキャラクターの分類には髪の色などの色情報が非常に重要な情報であり、色があることで認識率が上がりそう……という直感的な予想にも見合う結果となりました。
まとめ
今回は自作画像から学習を行う準備を整えると共に、実際にモデルを作って精度を確認してみました。
今回はAlexNetを扱いましたが、他のネットワーク等も試してみようと思います。


Be the first to comment on "Kerasで自作画像を用いてAlexNetで訓練するソースコード(Windows10)"