
今回は、以前の記事
Kerasで自作画像を用いてAlexNetで訓練するソースコード(Windows10)
に引き続いて、KerasでのDeep Learningをやっていきます。
今回は、学習したモデルのアーキテクチャや重みを保存し、それを読み込んで使う方法をやっていきたいと思います。
深層学習のプログラムを書いていると、結構プログラムを分けたい場面に遭遇します。例えば
① 訓練用のプログラム
② ①で訓練したモデルを用いたテストプログラム(正解不明のデータに適用) ⇒ 所謂本番用
みたいな感じに二つのプログラムになったりします。
このときに、①のプログラムでモデルのアーキテクチャや重みを保存しておいて、②のプログラムで読み込んで使うという流れになります。
今回は、アーキテクチャや重みの保存と読み込みの方法について見ていきましょう。
今回の環境
・OS : Windows10(64bit)
・GPU: GeForce GTX 1060
・Anaconda
・CUDA 9.0
・cuDNN v7.0.5
・Tensorflow 1.11.0
・Keras 2.2.4
上記全て環境構築済
モデルの保存(Save)方法
ここでは、過去記事である
Kerasで自作画像を用いてAlexNetで訓練するソースコード(Windows10)
で組んだAlexNetのプログラムを使い、このコードにモデルのアーキテクチャ・重みを保存するコードを加えることで、モデルを保存してみましょう。
ソースコードは以下となります。
追加した部分としては、後半の以下の部分のみとなります。
(1) モデルのアーキテクチャの保存
まずはモデルのアーキテクチャを保存します。アーキテクチャというのは、最初は畳み込み層があって、次に~層があって、フィルタの数は~で……のようなモデルの構造を示す部分です。
アーキテクチャを保存する方法ですが、JSON形式で保存する方法と、YAML形式で保存する方法の二つがあるようですが、どちらを選択しても特に大きな違いはなさそうです。
一応、上記のコードでは両方書きましたが、どちらか一方で保存すれば十分です。
model.to_json()で、モデルのアーキテクチャを示す文字列がmodel_arc_jsonに返却されるので、その文字列を保存してやるだけです。
YAML形式についても関数名が違うだけで全く同じなので割愛します。
せっかくなので、出力されたJSON形式のファイルと、YAML形式のファイルをメモ帳で見てみましょう。
<1> JSON形式

<2> YAML形式
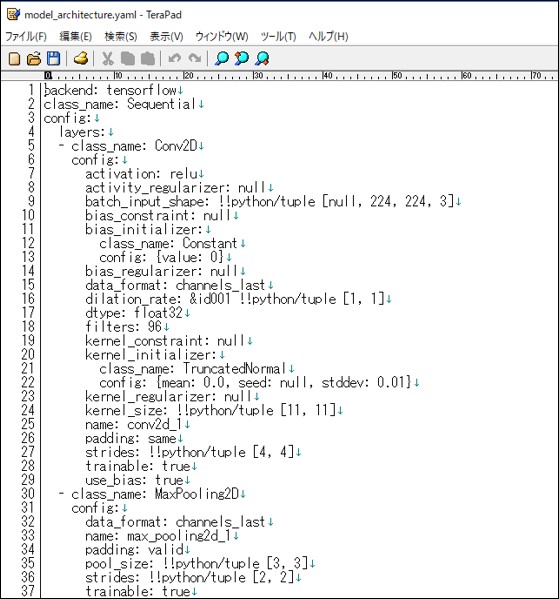
JSON形式は改行されておらず見づらいですが、正常に出力されているようです。
(2) モデルの重みの保存
次に重みの保存方法について見ていきます。
重みを保存することで、一度訓練することによって得た重みを保存し、次回その地点から訓練を再開したり、あるいは別のプログラムで使ったりすることができるようになります。
重みの保存も非常に簡単で、save_weightsを使い、HDF5(Hierarchical Data Format 5)で保存します。フォーマットの詳細については割愛します。
モデルの読み込み(Load)方法
上で保存したアーキテクチャに関するJSONファイルと、重みのファイルを基に、何か1枚の適当な画像(正解ラベルなし)を認識させるコードを作ってみました。
コードは上記のようになります。
最初に説明したセーブのコードと対応しているので、そちらで保存したアーキテクチャや重みをそのまま使えるはずです。
重要な部分だけ取り出して説明すると、
上記の部分にて、JSONファイルからモデルのアーキテクチャと重みを得ています。
アーキテクチャの方は、一度openで開くことでアーキテクチャの文字列を得て、その文字列をmodel_from_json()で読み込むことでモデルのアーキテクチャを取得できます。この流れは保存の部分と同じです。
実行結果
私の手元での実行結果です。
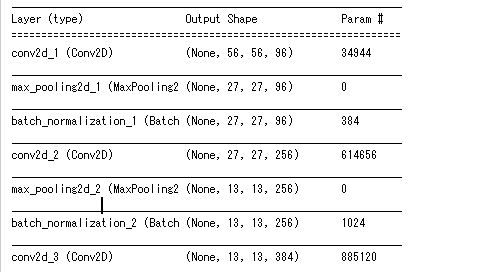
まず、ソースコード53行目のmodel.summary()の結果、全部は写していませんが、以下のように正常にモデルのアーキテクチャが表示されました。
また、今回使用したテスト画像(..\\test_dataset\\test_image.jpg)ですが、以下の画像を使用しました。

こちらの画像を認識させた結果、コンソールの表示が以下となりました。

見方ですが、まずresultの方には、各クラスの確率が入っています。resultを全て足すと1になるはずですが、最初の項目が最も高いスコアを示していることがわかります。
max_indexは、resultの中の0番のクラスが最高値でしたということを示しています。配列なので、インデックスは基本的に0番から9番までの10クラスです。
さて、肝心の0番が何だったかということですが、これは訓練したときのソースコードの
を見ればよく、0番のクラスは「“000_hatsune_miku“」です。
つまり、このテスト画像は初音ミクであると認識されており、概ね結果は正しいのではないでしょうか。
今回は訓練に使っていない画像をテストに使ったので、モデルにある程度の汎化性能があることもわかります。
おそらくですが、多少訓練画像とのタッチが違っても、髪色が実際の初音ミクと一致しているのが大きいのではないかと思います。
まとめ
今回はモデルのアーキテクチャと重みを一度外部ファイルに吐き出して、他のコードでそれを読み込んで使うということをやりました。
これで、一度訓練に使ったモデルや、取得した重みを保存しておくことが可能になります。
Be the first to comment on "Kerasで作成したモデルのアーキテクチャと重みの保存/読み込み方法"