ThrustはCUDA C++のテンプレートライブラリで、CUDAをインストールすると自動的に付いてくるライブラリです。
これはC++のSTL(Standard Template Library)と呼ばれるC++の開発でよく使われる標準ライブラリと似た文法で書けることが特徴で、通常のCUDAのプログラミングと比較すると、CPUからGPU側へのデータの転送などを簡易な文法で実現することができます。
よってThrustを使うことで、C++に慣れている人にとっては比較的少ない労力でCUDAを用いたGPUプログラミングをすることができます。
一方、実装されている処理には限りがあり、何でもできるわけではありません。Thrustに実装されている機能の例としては、配列の総和を求めたり、配列をソートしたりする機能が挙げられます。
結論、Thrustだけでしたいことが全て実現できるということは多くないと思いますが、CUDA C++の開発の中で、ThrustでできることはThrustで書いてしまうことで、開発スピードを高めることができると思います。
本記事では、Thrustの中に実装されている機能の一つであるソート機能についてピックアップし、使い方を紹介しようと思います。
Thrustで配列の値をソートするプログラムの例
以下にThrustで配列の値をソートするプログラムの例を紹介します。
#include <iostream>
#include <algorithm> // For STL sort
#include <thrust/sort.h> // For thrust sort
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
int main()
{
// Creating vector with random numbers
const int N = 100;
thrust::host_vector<int> h_vec(N);
for (int i = 0; i < N; i++) {
h_vec[i] = rand();
}
// Data transfer (CPU -> GPU)
thrust::device_vector<int> d_vec(N);
thrust::copy(h_vec.begin(), h_vec.end(), d_vec.begin());
// Sort (thrust)
thrust::sort(d_vec.begin(), d_vec.end()); // Sort by thrust
// Data transfer (GPU -> CPU)
thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());
// Confirmation
for (int i = 0; i < N; i++) {
std::cout << h_vec[i] << " ";
}
return 0;
}簡単に解説ですが、ソートの実行部分は21行目の「thrust::sort(d_vec.begin(), d_vec.end());」の部分です。使用するためには「thrust/sort.h」をインクルードする必要があります。
また、17~18行目でCPU(ホスト)側で作成したN個の乱数をCPU(ホスト)からGPU(デバイス)に転送し、24行目でGPU(デバイス)側でソートした結果をホスト側に戻しています。
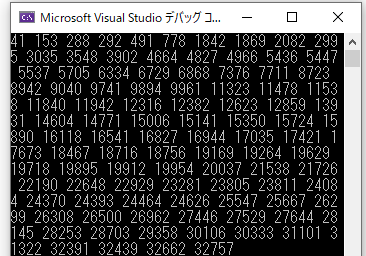
実行結果を以下に示します。ソートができていることが確認できました。
C++ STLのソート VS thrustのソート
thrustのソートが速いのかを確認するために、C++のSTLのソートと比較してみます。念のためSTLのソートのコードは以下です。
#include <iostream>
#include <algorithm> // For STL sort
#include <vector>
int main()
{
// Creating Array with random numbers
const int N = 100;
std::vector<int> h_vec(N);
for (int i = 0; i < N; i++) {
h_vec[i] = rand();
}
// Sort by C++ STL
std::sort(h_vec.begin(), h_vec.end());
// Confirmation
for (int i = 0; i < N; i++) {
std::cout << h_vec[i] << " ";
}
return 0;
}配列に格納する乱数の数(N)を変更することで、ソートに掛かる比較してみます。
今回、thrust版はホスト-デバイス間のメモリ転送の時間は含んでいません。既にデータがデバイス側に置いてあり、そこにthrustを使って処理する場合の処理時間と考えてください。
計測に利用した計算機のスペックはCPUがCore i7 6700、GPUがGeForce GTX 1060のものを利用しました。
| N | thrust sort [ms] | C++ STL sort [ms] |
| 10000 | 0.221 | 0.865 |
| 100000 | 0.357 | 8.315 |
| 1000000 | 1.646 | 65.447 |
| 10000000 | 8.088 | 646.056 |
ソートのような処理はGPUでの並列処理に向かないかと思ったのですが、thrustのソートは十分に高速で、データ転送の時間等を加味しても十分に使えるレベルにありそうです。
Thrustのソート関数のその他の機能
降順にソートする方法
デフォルトだと昇順でソートされてしまうので、降順にしたい場合には第3引数に「thrust::greater<型>()」を指定します。
thrust::sort(d_vec.begin(), d_vec.end(), thrust::greater<int>());Stable Sortする方法
thrustのソートではStable Sort(ソートの際に値が同じだった場合は、元の配列内の順番が保持されるソート)を行うこともできます。
方法は、関数の名前を「sort」ではなく「stable_sort」に変更するだけです。
thrust::stable_sort(d_vec.begin(), d_vec.end());キーとなる配列に基づいてソートする
意外と使うのがこの機能で、例えば配列が2つ以上の要素を持つときに、1つ目の要素の値を元にソートするようなことができます。
例えば、人の名前と点数の組から成る配列があったときに、点数をキーに人の名前を並び替えるような用途で使えます。
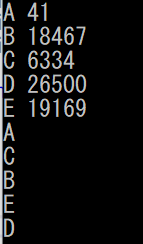
以下にサンプルとなるソースコードを示します。A~Eという文字に対して、乱数で数字を割り当てます。この数字に基づいて、昇順にA~Eという文字が並び替えられます。
#include <iostream>
#include <thrust/sort.h> // For thrust sort
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
int main()
{
// Creating vector with random numbers
const int N = 5;
thrust::host_vector<int> h_vec(N);
thrust::host_vector<char> h_vec_s(N);
h_vec_s[0] = 'A';
h_vec_s[1] = 'B';
h_vec_s[2] = 'C';
h_vec_s[3] = 'D';
h_vec_s[4] = 'E';
for (int i = 0; i < N; i++) {
h_vec[i] = rand();
std::cout << h_vec_s[i] << " " << h_vec[i] << std::endl;
}
// Data transfer (CPU -> GPU)
thrust::device_vector<int> d_vec(N);
thrust::device_vector<char> d_vec_s(N);
thrust::copy(h_vec.begin(), h_vec.end(), d_vec.begin());
thrust::copy(h_vec_s.begin(), h_vec_s.end(), d_vec_s.begin());
// Sort (thrust)
thrust::sort_by_key(d_vec.begin(), d_vec.end(), d_vec_s.begin()); // Sort by thrust
// Data transfer (GPU -> CPU)
thrust::copy(d_vec_s.begin(), d_vec_s.end(), h_vec_s.begin());
// Confirmation
for (int i = 0; i < N; i++) {
std::cout << h_vec_s[i] << std::endl;
}
return 0;
}以下が実行結果です。数字は昇順で41→6334→18467→19169→26500ですから、これをキーに文字がA→C→B→E→Dの順に並び替えられます。