Kdtree(k-dimensional tree)は、k次元のユークリッド空間にある点を分類する空間分割データ構造です。
用途は、最近傍探索の高速化などの用途で用いられます。最近傍探索とは、ある与えられた点の集団に対して、ある位置から最も近い点を探索する問題です。
解きたい問題は、例えば以下のような問題設定です。
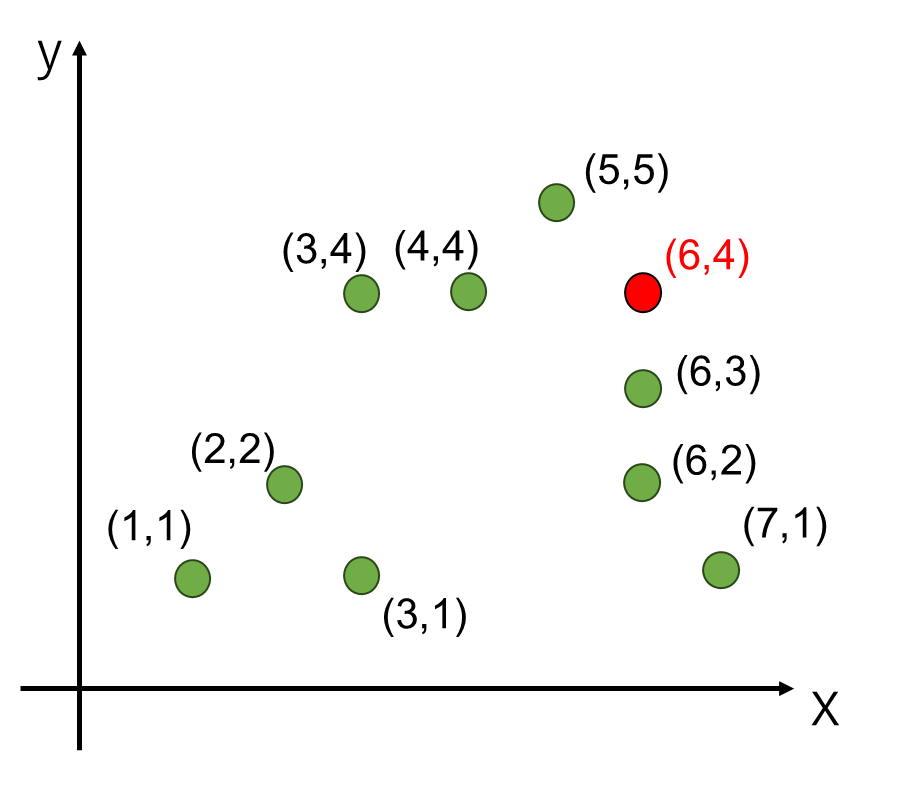
事前に緑の点が9つ与えられています。その後、(6,4)の位置にある赤の点から最も近い点を求めたいとします。
緑の点が9点しか無ければ、赤の点と緑の点の距離7パターンを全て計算して、一番小さいものを選択すればいいのでは? と思いますが、例えば緑の点が100万点ある場合、100万回距離計算をして最も近い点を求める必要があります。
また、近傍を求めたい赤の点が1個ではなく、赤の点も100万個入ってくるとすれば、100万×100万回の距離計算が必要です。
このような総当たりの方法(Brute force)に対して、kdtreeは一度木構造を作ってしまえば、その後の近傍探索が高速がに行える利点がある手法です。
まとめると、Kdtreeは近傍探索の高速化を行える可能性があるデータ構造であるということです。
目次
kdtreeを用いた近傍探索の処理方法
Kdtreeを用いて近傍探索を行うためには、以下の2つの処理が必要です。
- Kdtreeの構築
- Kdtreeを用いた近傍探索
まず初めに木を作ります。その後に、木を使って近い点を探索します。この二つの処理に分けて解説します。
ちなみに、距離を計算する対象の集合(上の図で緑の7点)は変化せず、赤の点が順次入ってきて距離を計算するような場合には、木の構築は1回だけでOKです。
Kdtreeの構築
Kdtreeの構築においては、空間を、所定の軸で分割していきます。
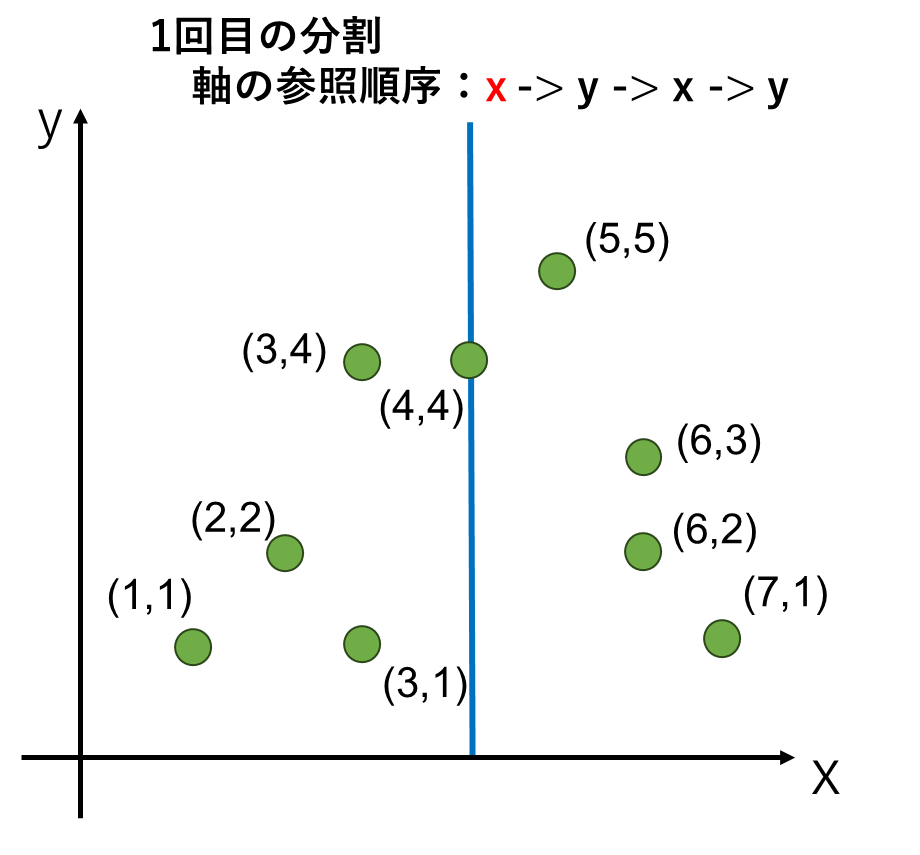
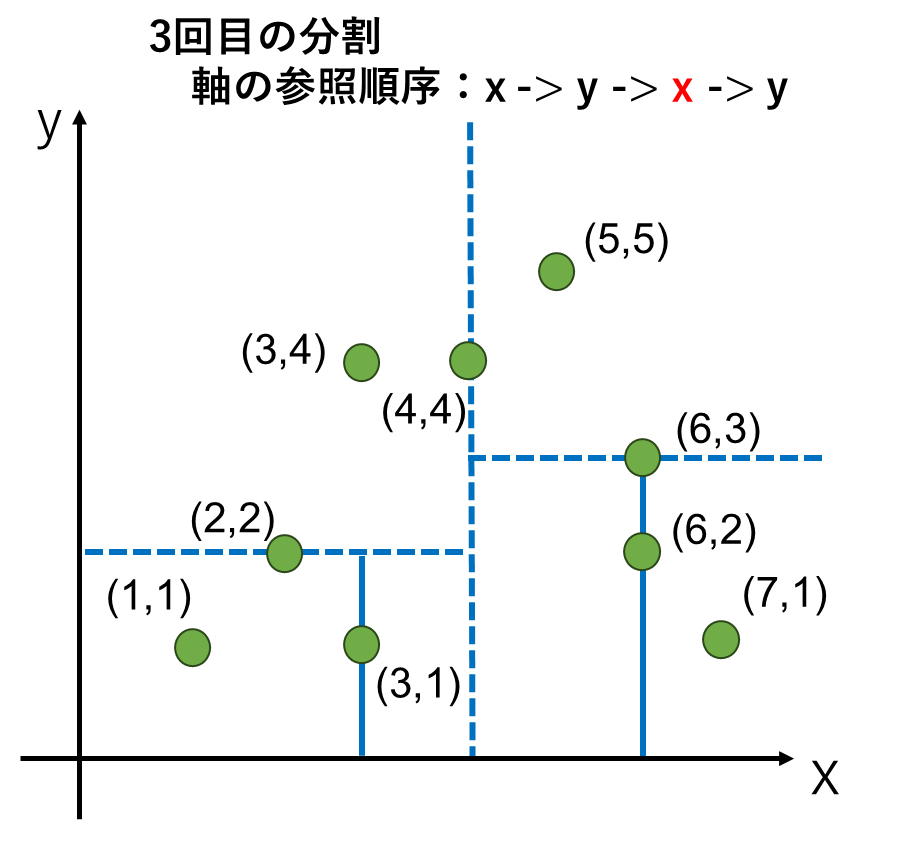
まず、分割に使う軸を事前に決めておきます。これは2次元であれば、最初の分割でx軸の値を見る、次の分割ではy軸の値を見る、すなわちx軸→y軸→x軸→y軸と交互の順序で見ると事前に決めておきます。
分割は、各軸の値の中央値を基に分割することが多いようです。以下の図を見ていただいた方が視覚的に理解できると思います。
まず、1回目の分割はx軸の値を参照します。この中央値を取ると4が中央値になります。つまり左側に4点、右側に4点に分割されます。
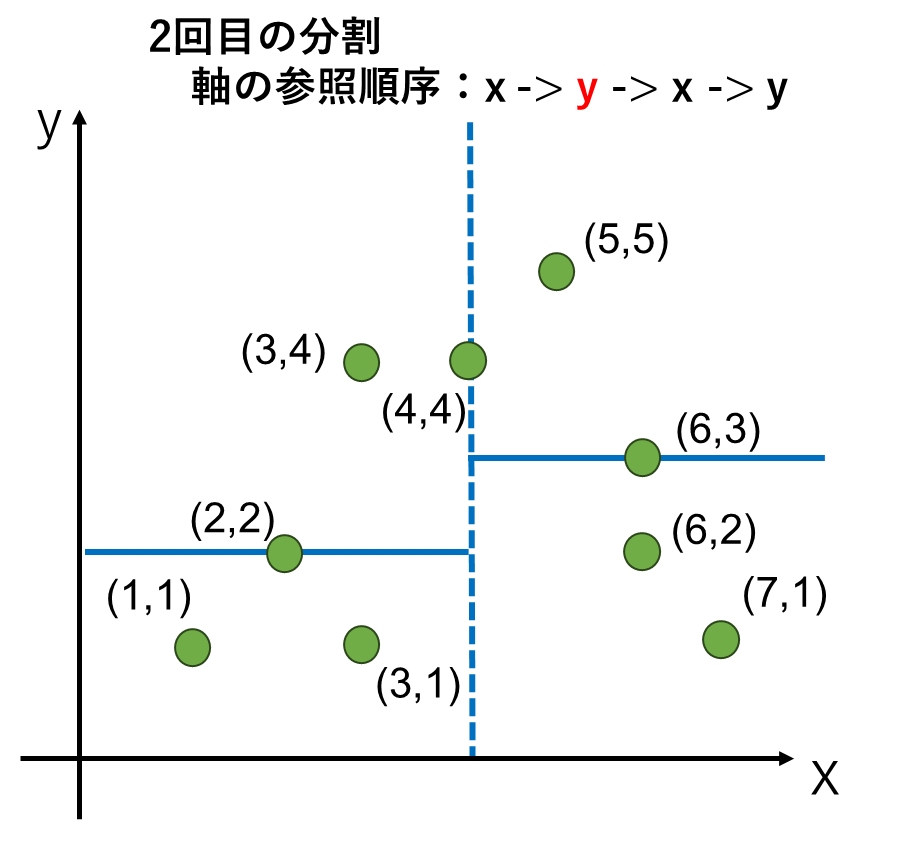
2回目の分割はy軸の値を参照します。このとき、最初に分けた左側と右側それぞれに対して分割します。分割する位置は左と右で異なっても構いません。
2回目の分割は左、右共に4点ずつあるので、厳密な中央となる点は求まりません。y軸の値が2番目 or 3番目に大きい点で、最初に分割に使った(4,4)に近い点にするとしておきましょう。ここは、プログラム等を実装する上で決めごとの問題なので、こうしなければならないというのは特にありません。
最後に、またx軸の値を参照して分割します。既に1点になっているところはそのままにして、2点残っているところは、以前に分割した点に近いところを選んで分割しました。
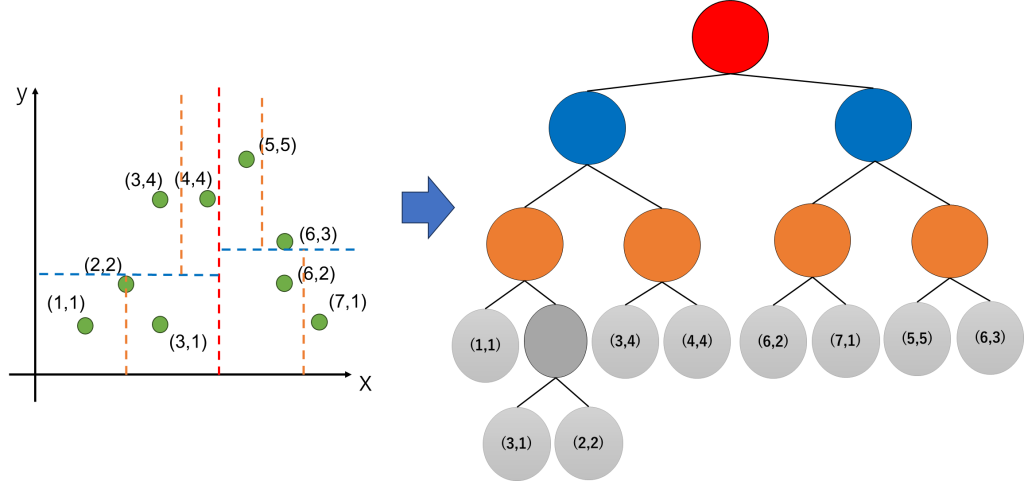
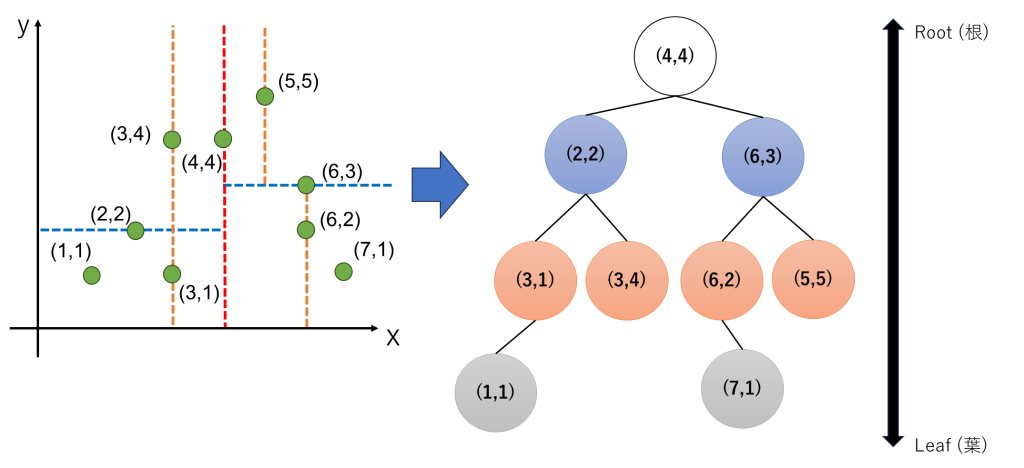
ここまでの分割結果を木構造に落としこみます。以下の図の右側の構造がkdtreeとなります。
Kdtreeを用いた近傍探索
さて、木を作った後に、どうやって近傍探索をするのかについて確認したいと思います。ここでは、最も簡単な最近傍探索(1番近い点を見つける探索)に言及します。
最初に述べた(6,4)の位置の点に最も近い点を探索してみます。
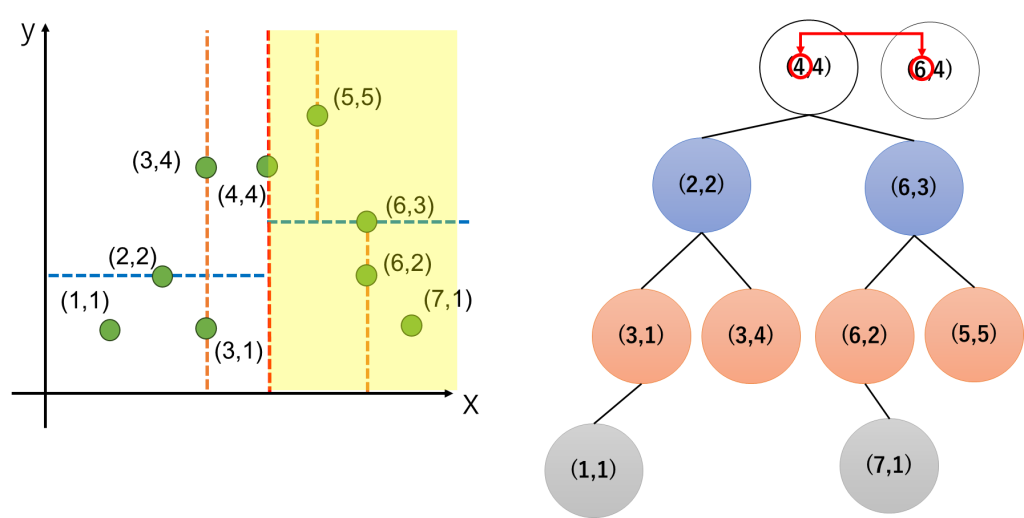
まず、(6,4)の値を参照して(6,4)が分割のどこにあるかを確認します。ここでは、木を作成するのと同じようにx軸→y軸→x軸→y軸と交互の順序で値を見ていきます。
まず、(6,4)のxの値6は、最上位の(4,4)のxの値4より大きいわけですから、ここのxの値を比較するだけで右側のゾーンにあることがわかりますね。
次に、右側のゾーンを上下に分ける(6,3)の点とy軸の値を比較すると、(6,4)は上側の領域にあることがわかります。
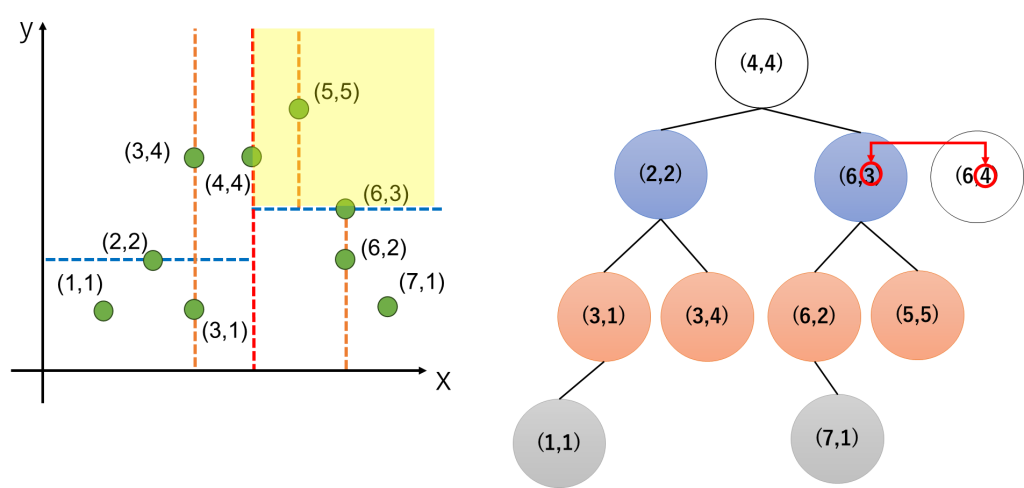
つまり、(5.5)の点と同じブロックにあることがわかります。
そこで、まずは(5,5)を第一候補として(5,5)と(6,4)のユークリッド距離を計算します。これはルート2になります。よってこの時点の最小距離をルート2とします。
しかしながら、この(5,5)が最小距離とは限りません。よって、後は木を上に遡り存在するノードとの距離を計算します。
まずは(6,3)を確認します。ここでは分割に用いたyの値を比較すると、距離が1であることがわかります。よって、現在の最小距離であるルート2より小さいため、(6,3)の下にある点は最小距離となる可能性を含みます。そのため、(6,3)の下にある点及び自身(すなわち(6,3), (6,2), (7,1), (5,5))を候補とします。
これを図で書くと以下の左下の図の通りで、最小距離候補の(5,5)との距離はルート2なのですが、ルート2という距離は、(6,3)の点で分割した領域を跨いで下側の領域に溢れます。よって、(6,3)で分割した下側の領域にも近い点があるかもしれないよね、ということになります。
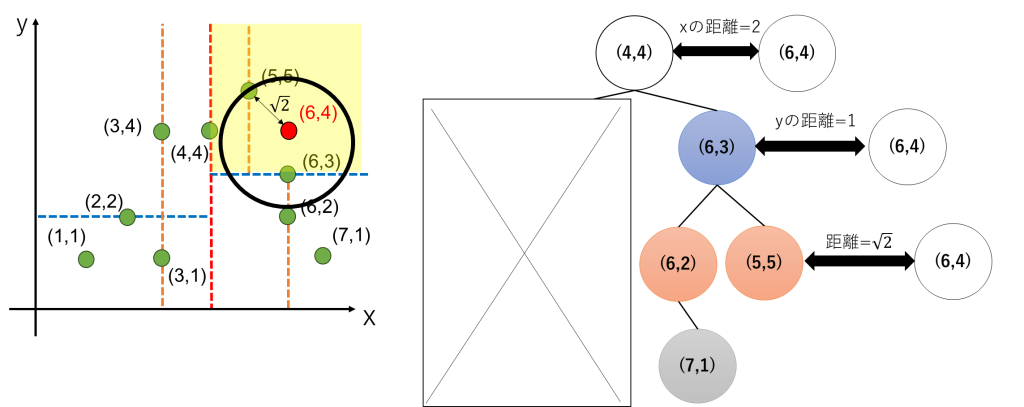
よって、(6,3)の下にある点及び自身(すなわち(6,3), (6,2), (7,1), (5,5))への距離を考えると、候補の中で(6,4)に一番近い点は(6,3)であり、ユークリッド距離は1になります。よって、この時点の最小距離を1とします。
次にノード(4,4)を確認します。(4,4)へのxの距離は2で、これは最小距離1を上回っていますから、理由は省略しますが(4,4)の左側にあるノードが(6,4)に最近傍になることはありません。
よって、最も近い点は(6,3)であり、このときの最小距離1が最近傍への距離です。すなわち、Kdtreeでの最近傍検索では、どの点が一番近いかに加えて、距離も同時に求めることができます。
今回は小さい木なので、全体9点のうち4点にしか絞り込めていませんが、点数が大きくなれば、かなり点数を絞り込むことができ、大幅に計算時間を削減することができます。
kdtreeのデメリット
kdtreeを使うデメリットは、次元数が多い場合の高速化効果が見込めないことです。
今回は2次元を例にとって説明しました。2次元や3次元であれば良いですが、100次元などの高次元で考えた場合には、探索するデータの絞り込みの効率が良くなく、効果が薄れるそうです。
画像処理や3D処理などの少ない次元のデータに対してはkdtreeは有効と言えるでしょう。
また、木を作る時間が必要ですから、点数が少ない場合は総当たりで計算して、計算をCUDAで並列化とかをしてしまった方が早いかもしれませんね。
kdtreeを用いた近傍探索の処理の補足
分割に際しての中央値の利用について
必ずしも中央値を使う必要はないですが、中央値を使うモチベーションは、分割した際に分けられた二つのグループそれぞれが含む点の数がほぼ同じになることです。
よって、kdtreeを構築したときに極端に深い葉(Leaf)ができてしまうことを防ぐことができ、探索に掛かる時間が安定します。
一方、中央値自体は求める場合にソート等が必要で、平均値などと比べると少々リッチな処理です。そのため、中央値ではなく、平均値を使っても良いです。
ここで一つ疑問となってくるのは、平均値を用いた場合、中央値と異なり、平均となる位置に対応する点がないこともあるわけですが、どのように木を構築するのだろうということです。
これも様々なやり方がありますが、下の図のように平均となる点で領域を分けて、全て点はLeafの部分に付くように構築する方法もあるようです。
つまり、kdtreeと一言で言っても、分割に何を採用するのかとか、軸を参照する順番とかによって構築される木が変わるので、木は一意に決まるわけではないようです。