本記事では、グラフ構造を利用したグラフニューラルネットワークを紹介し、Pytorchを利用した実装方法を紹介します。内容は入門者向けのものとなっています。この記事を読むことでグラフニューラルネットワークの概要を理解し、Pytorchを使ってグラフニューラルネットワークのプログラムの開発を始められるようになります。
目次
グラフ構造とは
グラフニューラルネットワークとは、グラフを入力にしたニューラルネットワークです。まず、このグラフというデータ構造の概要を説明します。
グラフの構成要素
グラフニューラルネットワークで扱うグラフ構造とは、ノード(頂点)とノード間の接続関係を表すエッジ(辺)の集合から成るデータ構造です。グラフニューラルネットワークを利用するためには、まずこのようなグラフデータが必要になります。
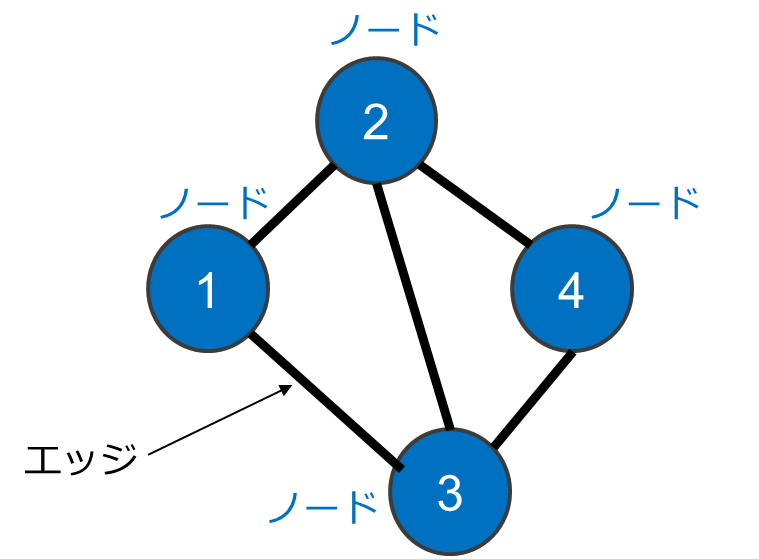
世の中にグラフ構造を持つデータは多数あります。例えばTwitter(X)やFacebookなどのSNS上の人間関係は、ノードを人として、エッジをフォロワーや友人関係を捉えることでグラフデータと見なすことができます。
もともとグラフ構造になっていない場合にも、距離が近いノードを繋ぎ合わせることでグラフにできるケースがあります。例えば、地図上のさまざまな地点(ノードと見なす)で計測した気温のデータがある場合に、距離が〇㎞以下のノード同士を繋ぐという処理をすれば、グラフデータとして扱うことができます。
また、最近は3Dの人のアバターなどをVR向けなどに表示する際に、ポイントクラウド(点群)データが使われることがあります。ポイントクラウドは色付きの大量な微小な点の集合で、3Dのオブジェクトを表現するデータ形式です。点群データそのものは接続関係を持ちませんが、距離が近い点同士を繋いでしまえばグラフになります。
どうやってグラフを作るかも重要なポイントではありますが、ここでは既にグラフが構築されているものとして話を進めます。
グラフの種類:有向グラフと無向グラフ
グラフにはさまざまな種類がありますが、大きな一つの分類方法に有向グラフと無向グラフがあります。
有向グラフは接続関係が方向を持つグラフです。道路に一方通行の道があるように、あるノードAからノードBに接続があったとしても、ノードBからノードAへの接続がないケースが許容されるのが有向グラフです。必ずしも相互にフォローし合うわけではないTwitter(X)での人間関係は有向グラフです。

逆に、以下の図のように、方向がないのが無向グラフです。片方が友達申請をし、承認することで友達関係になるFacebookの人間関係は無向グラフです。

グラフニューラルネットワークでは、有向グラフも無向グラフも扱うことができます(無向グラフは有向グラフの特殊なケースと捉えることもできます)。
グラフのノード(頂点)は値を持つ
グラフ構造とは、ノード(頂点)とノード間の接続関係を表すエッジ(辺)の集合から成るデータ構造と言いましたが、一般にノードは何らかの値を持ちます。
例えば、友達関係の例であれば「年齢」はノードが持つ値と言えます。

グラフニューラルネットワーク (Graph Neural Network)
グラフニューラルネットワーク (Graph Neural Network, GNN) はグラフで表現されているデータを深層学習で扱うためのニューラルネットワーク手法の総称です。
通常のニューラルネットワークにさまざまな種類のネットワーク手法があるように、GNNにも多数のネットワーク手法があり、そして今も研究が進められています。例えば、大別するだけでもRecurrent Graph Neural Networks (RecGNNs)や、畳み込みグラフニューラルネットワークやグラフオートエンコーダーなどがあります。
以下の表を引用したサーベイ論文に詳しく分類が掲載されていますので、興味のある方はチェックしてみるとよいでしょう。
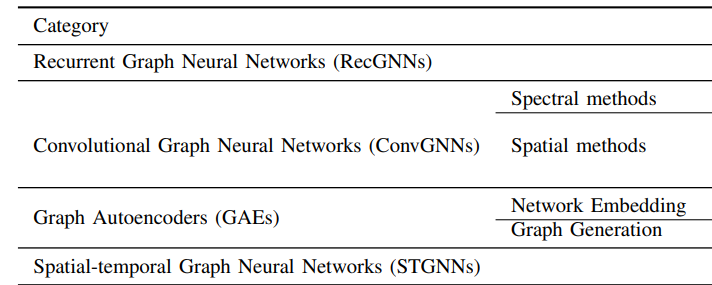
それぞれのネットワークモデルに関して詳しい解説は本記事では行いませんが、グラフニューラルネットワークは (1) グラフを対象としたニューラルネットワークであること (2) グラフの接続関係を考慮した予測ができる という点を押さえておくとよいでしょう。
どんなタスクを解決できる?
GNNは、グラフに関連する多様なタスクを解決できます。主に「Node classification」「Graph classification」「Link prediction」があります。
Node classification
各々のノード(頂点)を何らかのクラスに分類することができます。例えば、一部のノードに正解ラベルが割り当てられ、他のノードのクラスを予測することができます。
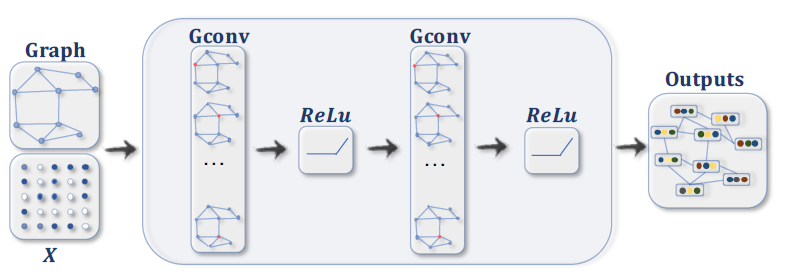
Graph classification
グラフ全体の情報から、グラフを分類するGraph classsificationのようなタスクも実現することができます。例えば化合物の構造式からグラフを作り、その化合物が有害であるか無害であるかを判別するなどの用途に使うことができます。
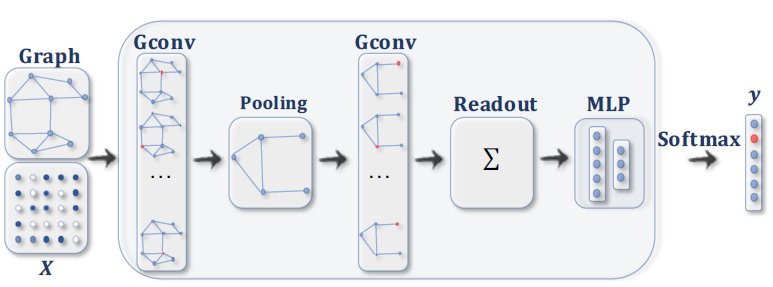
Link prediction
Link predictionでは、未知のノード同士の繋がりを予測することができます。オンラインショッピングのレコメンドシステムなどにおいて、既存の購入履歴をグラフで表現し、おすすめの商品を未知の接続として見出すなどの用途で使うことが可能です。
PyG (Pytorch Geometric) 環境構築
PyG(Pytorch Geometric)は、Pytorch上で動作するグラフニューラルネットワークの研究と開発を加速するために設計された拡張ライブラリです。今回はPyG(Pytorch Geometric)を使って実装を行います。
環境構築の手順としては、私はWindows環境でAnacondaを利用し、①Pytorchのインストール、②Pytorch Geometricのインストールの順で作業しました。
Pytorchのインストール
以下のPytorch公式サイトより自身の環境に合ったPytorchをインストールします。特にこだわりがなければ、なるべく新しいバージョンをインストールすればよいでしょう。
外部サイト:Pytorch公式 – Start Locally
PyG (Pytorch Geometric) のインストール
以下のサイトからPyGのインストールの情報を得ることが可能です。
外部サイト:Installation — pytorch_geometric documentation
conda環境でインストールしたかったのですが、conda packagesはWindowsでは現在利用できない(Conda packages are currently not available for Windows and M1/M2/M3 macs.)とのことで、仕方なくpipでインストールしました。
pip install torch_geometric動作確認
こちらのページにあるチュートリアルコードを実行し、エラーが出ないことを確認しました。
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)PyG (Pytorch Geometric) でGNNを実装
本記事ではシンプルなグラフニューラルネットワークを動かし、何らかの課題解決を行うところまでを実施したいと思います。
今回対象とするタスクはNode Classificationと呼ばれる、各ノードを特定のクラスに分類するタスクです。半教師あり分類問題とも呼ばれ、グラフ構造とノードの特徴量、少数のノードの正解ラベルが与えられ、残りのノードのラベルを推定することが目的となります。
今回の実験で使用するデータセットでは、各ノードが一つの論文を表し、接続関係は論文同士の引用関係を表します。解決すべきタスクとしては、その論文が何の分野に関するものであるのかを分類します。
本章では手順を踏んでソースコードの内容を解説しますが、最初に全てのソースコードを見たいという方のために以下に全てのコードを掲載します。基本は公式のチュートリアルを参考にさせていただきました。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
# Loading data
dataset = Planetoid(root='/tmp/Cora', name='Cora')
print('Dataset.num_node_features:',dataset.num_node_features)
print('Dataset.num_classes:',dataset.num_classes)
print('The number of nodes: ',dataset[0].num_nodes)
print('The number of edges: ',dataset[0].num_edges)
print('The number of nodes for training: ',dataset[0].train_mask.sum())
print('The number of nodes for test: ',dataset[0].test_mask.sum())
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')データセットの読み込み
初めに今回の実験に使うデータセットを獲得します。3Dの点群データのように、点の集合からグラフを構築するフローが必要なデータもありますが、ここでは簡単のために既にグラフ構造が構築済のデータセットを利用します。
使用するデータセットは、PyGに既にデータセットを読み込む関数が実装されているPlanetoidデータセットを使用します。Planetoidデータセットは論文「Revisiting Semi-Supervised Learning with Graph Embeddings」で導入されたデータセットで、Planetoidデータセットの中に何種類かのグラフが用意されていますが、”Cora”というグラフを今回利用します。
”Cora”は2708個のノード(頂点、データ)と、10556本のエッジ(接続)から成るグラフ構造です。各ノードは、ある出版物(論文)を表します。エッジは引用ネットワークを示します。すなわち、ある論文Aが論文Bを引用している場合、論文Aから論文Bへの接続があると見なします。
そして、各論文は7種類の分野に分類されています。すなわち本タスクの最終的な目的は、各論文がこの7つの分野のどれに当てはまるのかを突き止める論文の分類問題ということになります。
GNNを利用して、引用関係を元にして分野が近い論文を考慮してクラス推定をすることで、精度が上がりそうなことは間隔として理解できると思います。
そして各論文は、事前に設定された1433個の単語が論文内で使われているかどうか(0 or 1の情報)を示す1433次元のベクトルを持ちます。すなわち、2708個の論文に対して、1433個のワードが使われているか、使われていないかという情報を持つため、合計2708(個)×1433(次元)の入力データです。
このPlanetoidデータセットのCoraグラフを読み込むコードは以下の通りです。print(~)の部分は確認しているだけなので、データセットの読み込みは「dataset = Planetoid(root=’/tmp/Cora’, name=’Cora’)」で実現できます。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
# Loading data
dataset = Planetoid(root='/tmp/Cora', name='Cora')
print('Dataset.num_node_features:',dataset.num_node_features)
print('Dataset.num_classes:',dataset.num_classes)
print('The number of nodes: ',dataset[0].num_nodes)
print('The number of edges: ',dataset[0].num_edges)
print('The number of nodes for training: ',dataset[0].train_mask.sum())
print('The number of nodes for test: ',dataset[0].test_mask.sum())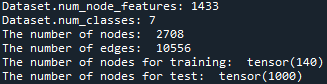
コードを実行すると、コンソールに上記の出力を得ます。訓練に使うノード(正解ラベルが分かっているノード)が140あり、未知の1000個のノードの値を推測します。グラフ構造と、各ノードが持つ値(1433個の論文内で使われている単語のデータ)は既知です。
ネットワークモデルの構築
Graph convolution(グラフ畳み込み)を利用したシンプルなネットワークモデルを構築します。第1層は1433次元のデータを、16次元に畳み込みます。第2層は16次元のデータを、クラスの数(7次元)に畳み込みます。活性化関数としてReLUを用います。
最終的に、各ノードが7つのクラスに対して、どれくらいそれらしいかという値をSoftmaxで出力します。これによりノードのクラスを推測することができます。
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)モデルの訓練
モデルの構築が終わったら、いよいよ訓練を行います。200エポックで、訓練データ(140ノード)のみを使ってモデルを訓練します。
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()分類結果(評価)の出力
最後に、クラス分類結果を評価します。
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
7種類のクラスを当てる問題ですが、約80%の正答率が得られていることがわかります。
ネットワークのアレンジ方法
今回の記事で紹介した「ネットワークモデルの構築」の箇所を変更することで、さまざまなネットワークアーキテクチャに関して、分類精度を確認することができます。
まとめ
今回の記事では、グラフニューラルネットワークの入門を行いました。Pytorch geometricを使うことでグラフニューラルネットワークを簡単に導入することができます。今回は、まず何かを動かしてみることに焦点を当てましたが、今後は自らが解決したいタスクにGNNを適用していきたいです。